

СТРАТЕГИИ БИЗНЕСА: АНАЛИТИЧЕСКИЙ СПРАВОЧНИК
Под общей редакцией академика РАЕН, д.э.н. Г.Б.
Клейнера
Москва, «КОНСЭКО»,1998
| Предыдущая |
Приложение 1. МЕТОДЫ СТАТИСТИЧЕСКОГО АНАЛИЗА И ПРОГНОЗИРОВАНИЯ В БИЗНЕСЕ
4. Математический инструментарий прогнозирования
Математические методы и модели, используемые в задачах стохастического анализа и прогнозирования в бизнесе, могут относиться к самым различным разделам математики: к регрессионному анализу, анализу временных рядов, формированию и оцениванию экспертных мнений, имитационному моделированию, системам одновременных уравнений, дискриминантному анализу, логит- и пробит-моделям, аппарату логических решающих функций, дисперсионному или ковариационному анализу, анализу ранговых корреляций и таблиц сопряженности и т. д. Однако все они объединены тем, что представляют собой различные подходы к решению центральной проблемы многомерного статистического анализа и эконометрики – проблемы статистического исследования зависимостей, которая, как раз, и является базовой проблемой статистического анализа и прогнозирования в бизнесе (ее общая формулировка была приведена в п. 2).
В п. 1 уже было замечено, что среди p + k + l + m компонент анализируемого
многомерного признака ![]() могут быть
как количественные, так и ординальные и номинальные переменные. Упомянутые выше
подходы к решению центральной проблемы многомерного статистического анализа
формировались именно с учетом природы исследуемых переменных. Соответствующая
специализация этих подходов отражена в табл. 4. В ней же даны ссылки на литературные
источники, в которых можно найти достаточно полное описание этих подходов.
могут быть
как количественные, так и ординальные и номинальные переменные. Упомянутые выше
подходы к решению центральной проблемы многомерного статистического анализа
формировались именно с учетом природы исследуемых переменных. Соответствующая
специализация этих подходов отражена в табл. 4. В ней же даны ссылки на литературные
источники, в которых можно найти достаточно полное описание этих подходов.
Таблица 4.
|
Природа результирующих показателей |
Природа объясняющих переменных |
Название обслуживающих разделов многомерного статистического анализа |
Литературные источники |
|
Количественная |
Количественная |
Регрессионный анализ и системы одновременных уравнений |
[1, гл. 15, 17] |
|
Количественная |
Единственная количественная переменная, интерпретируемая как «время» |
Анализ временных рядов |
[1, гл. 16] |
|
Количественная |
Неколичественная (ординальные или номинальные переменные) |
Дисперсионный анализ |
[4, гл. 13] |
|
Количественная |
Смешанная (количественные и неколичественные переменные) |
Ковариационный анализ, модели типологической регрессии |
[4, гл. 13] |
|
Неколичественная (ординальные переменные) |
Неколичественная (ординальные и номинальные переменные) |
Анализ ранговых корреляций и таблиц сопряженности |
[1, гл. 11] |
|
Неколичественная (номинальные переменные) |
Количественная |
Дискриминантный анализ, логит- и пробит-модели, кластер-анализ, таксономия, расщепление смесей распределений |
[1, гл. 12-15] |
|
Смешанная (количественные и неколичественные переменные) |
Смешанная (количественные и неколичественные переменные) |
Аппарат логических решающих функций, Data Mining |
[5] |
Тем не менее, практика статистического анализа и прогнозирования в бизнесе
свидетельствует о том, что во всем спектре их математического инструментария
бесспорное лидерство (по распространенности и актуальности) принадлежит трем
разделам:
- регрессионному анализу;
- анализу временных рядов;
- механизму формирования и статистического анализа экспертных оценок.
Кратко остановимся на каждом из этих разделов.
Регрессионный анализ
Как и прежде, будем описывать функционирование исследуемого реального объекта
(фирмы, компании, процесса производства или дистрибуции продукции и т. п.)
набором переменных ![]() и
и ![]() (их содержательный
смысл описан в п. 2). Введем ряд определений и понятий, используемых в
регрессионном анализе.
(их содержательный
смысл описан в п. 2). Введем ряд определений и понятий, используемых в
регрессионном анализе.
Результирующие (зависимые, эндогенные) переменные. Переменная
![]() , характеризующая
результат или эффективность функционирования анализируемой системы, называется
результирующей (зависимой, эндогенной). Ее значения формируются в процессе и
внутри функционирования этой системы под воздействием ряда других переменных
и факторов, часть из которых поддается регистрации и, в определенной степени,
управлению и планированию (эту часть принято называть объясняющими переменными,
см. ниже). В регрессионном анализе результирующая переменная выступает в роли
функции, значения которой определяются (правда, с некоторой случайной погрешностью)
значениями упомянутых выше объясняющих переменных, выступающих в роли аргументов.
Поэтому по природе своей результирующая переменная
, характеризующая
результат или эффективность функционирования анализируемой системы, называется
результирующей (зависимой, эндогенной). Ее значения формируются в процессе и
внутри функционирования этой системы под воздействием ряда других переменных
и факторов, часть из которых поддается регистрации и, в определенной степени,
управлению и планированию (эту часть принято называть объясняющими переменными,
см. ниже). В регрессионном анализе результирующая переменная выступает в роли
функции, значения которой определяются (правда, с некоторой случайной погрешностью)
значениями упомянутых выше объясняющих переменных, выступающих в роли аргументов.
Поэтому по природе своей результирующая переменная ![]() всегда стохастична
(случайна). В общем случае обычно анализируется поведение сразу нескольких
всегда стохастична
(случайна). В общем случае обычно анализируется поведение сразу нескольких
![]() результирующих
переменных
результирующих
переменных ![]() .
.
Объясняющие (предикторные, экзогенные) переменные ![]()
![]() . Переменные
(или признаки), поддающиеся регистрации, описывающие условия функционирования
изучаемой реальной экономической системы и в существенной мере определяющие
процесс формирования значений результирующих переменных, называются объясняющими.
Как правило, часть из них поддается хотя бы частичному регулированию и управлению.
Значения ряда объясняющих переменных могут задаваться как бы «извне» анализируемой
системы. В этом случае их принято называть экзогенными. В регрессионном анализе
они играют роль аргументов той функции, в качестве которой рассматривается анализируемый
результирующий показатель
. Переменные
(или признаки), поддающиеся регистрации, описывающие условия функционирования
изучаемой реальной экономической системы и в существенной мере определяющие
процесс формирования значений результирующих переменных, называются объясняющими.
Как правило, часть из них поддается хотя бы частичному регулированию и управлению.
Значения ряда объясняющих переменных могут задаваться как бы «извне» анализируемой
системы. В этом случае их принято называть экзогенными. В регрессионном анализе
они играют роль аргументов той функции, в качестве которой рассматривается анализируемый
результирующий показатель ![]() . По своей
природе объясняющие переменные могут быть как случайными, так и неслучайными.
. По своей
природе объясняющие переменные могут быть как случайными, так и неслучайными.
Регрессионные остатки ![]()
![]() – это
латентные (т. е. скрытые, не поддающиеся непосредственному измерению) случайные
компоненты, отражающие влияние соответственно на
– это
латентные (т. е. скрытые, не поддающиеся непосредственному измерению) случайные
компоненты, отражающие влияние соответственно на ![]() не учтенных
в составе
не учтенных
в составе ![]() факторов, а
также случайные ошибки в измерении анализируемых результирующих переменных.
Они, вообще говоря, тоже могут зависеть от
факторов, а
также случайные ошибки в измерении анализируемых результирующих переменных.
Они, вообще говоря, тоже могут зависеть от ![]() , т. е.
в общем случае
, т. е.
в общем случае ![]()
![]() .
.
Общая схема взаимодействия переменных в регрессионном анализе изображена на рисунке.
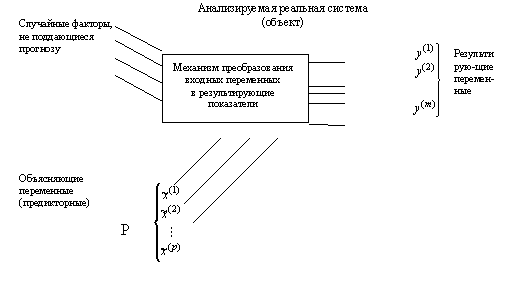
Рисунок. Общая схема взаимодействия переменных в регрессионном анализе.
Функция регрессии ![]() по
по
![]() . Функция
. Функция
![]() называется
функцией регрессии
называется
функцией регрессии ![]() по
по ![]() (или просто – регрессией
(или просто – регрессией
![]() по
по
![]() ), если она
описывает изменение условного среднего значения результирующей переменной
), если она
описывает изменение условного среднего значения результирующей переменной
![]() (при условии,
что значения объясняющих переменных
(при условии,
что значения объясняющих переменных ![]() зафиксированы
на уровнях
зафиксированы
на уровнях ![]() ) в зависимости
от изменения значений
) в зависимости
от изменения значений ![]() объясняющих
переменных. Соответственно математически это определение может быть записано
в виде
объясняющих
переменных. Соответственно математически это определение может быть записано
в виде
![]()
![]()
![]() ,
,
где символ ![]() означает операцию
теоретического усреднения значений
означает операцию
теоретического усреднения значений ![]() (т. е.
(т. е.
![]()
![]() – это
математическое ожидание случайной величины
– это
математическое ожидание случайной величины ![]() , а
, а ![]()
![]() , или просто
, или просто
![]()
![]() – это
условное математическое ожидание случайной величины
– это
условное математическое ожидание случайной величины ![]() , вычисленное
при условии, что значения объясняющих переменных
, вычисленное
при условии, что значения объясняющих переменных ![]() зафиксированы
на уровне
зафиксированы
на уровне ![]() ).
).
Если мы анализируем одновременно ![]() результирующих
переменных
результирующих
переменных ![]() , то следует
рассмотреть соответственно
, то следует
рассмотреть соответственно ![]() функций регрессий
функций регрессий
![]()
![]()
![]()
![]()
![]() или, что то
же, одну векторнозначную функцию
или, что то
же, одну векторнозначную функцию
![]()
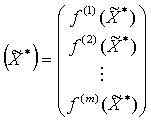 . (11)
. (11)
Тогда модель регрессии ![]() по
по ![]() может быть
записана в виде
может быть
записана в виде
![]()
![]()
![]()
![]()
![]() , (12)
, (12)
причем, из определения ![]()
![]() следует, что
всегда]
следует, что
всегда]
![]() (12’)
(12’)
(тождественный знак равенства в (12’) означает, что оно справедливо
при любых значениях ![]() ; вектор-столбец
из нулей в правой части имеет размерность
; вектор-столбец
из нулей в правой части имеет размерность ![]() ).
).
В рамках введенных понятий и обозначений задача регрессионного анализа в самом общем виде может быть сформулирована следующим образом:
по результатам ![]() измерений
измерений
![]()
исследуемых переменных на ![]() объектах (системах,
процессах) анализируемой совокупности построить такую (векторнозначную) функцию
(11), которая позволила бы наилучшим (в определенном смысле) образом восстанавливать
значения результирующих (прогнозируемых) переменных
объектах (системах,
процессах) анализируемой совокупности построить такую (векторнозначную) функцию
(11), которая позволила бы наилучшим (в определенном смысле) образом восстанавливать
значения результирующих (прогнозируемых) переменных ![]() по заданным
значениям объясняющих (экзогенных) переменных
по заданным
значениям объясняющих (экзогенных) переменных ![]() .
.
З а м е ч а н и е 1. Наиболее
распространенными являются линейные модели регрессии, т. е. модели,
в которых функции регрессии ![]() имеют линейный
вид:
имеют линейный
вид:
![]() (12’’)
(12’’)
З а м е ч а н и е 2. Существует
по меньшей мере два варианта интерпретации введенных в п. 2 «поведенческих»,
«статусных» и «внешних» переменных, соответственно, ![]() и
и ![]() в рамках описанной
модели регрессии (12)–(12’). В первом варианте все три типа переменных
в рамках описанной
модели регрессии (12)–(12’). В первом варианте все три типа переменных
![]() и
и ![]() относят к объясняющим
переменным и строят регрессию
относят к объясняющим
переменным и строят регрессию ![]() по
по ![]() . В другом
варианте переменные
. В другом
варианте переменные ![]() и
и ![]() интерпретируют
как условия проведения наблюдений и тогда отдельно для каждого
фиксированного сочетания этих условий строят регрессионную модель вида (12)
(в рамках линейной модели (12’’) это будет означать, что сами коэффициенты
регрессии
интерпретируют
как условия проведения наблюдений и тогда отдельно для каждого
фиксированного сочетания этих условий строят регрессионную модель вида (12)
(в рамках линейной модели (12’’) это будет означать, что сами коэффициенты
регрессии ![]() зависят от
зависят от
![]() и
и ![]() , т. е.
определяются как функции от
, т. е.
определяются как функции от ![]() и
и ![]() ).
).
Анализ временных рядов
Всякий статистический анализ и прогноз основывается на исходных статистических
данных. Их основные типы были представлены в п. 1. При этом, если процесс
регистрации данных происходит во времени ![]() , и само время
фиксируется наряду со значениями анализируемых характеристик
, и само время
фиксируется наряду со значениями анализируемых характеристик ![]() , то говорят
о статистическом анализе так называемых панельных данных. Если зафиксировать
номер переменной
, то говорят
о статистическом анализе так называемых панельных данных. Если зафиксировать
номер переменной ![]() и номер статистически
обследуемого объекта
и номер статистически
обследуемого объекта ![]() , то расположенную
в хронологическом порядке последовательность значений
, то расположенную
в хронологическом порядке последовательность значений
![]() (13)
(13)
называют одномерным временным рядом. Если же одновременно рассматривать
![]() одномерных
временных рядов вида (13), т. е. исследовать закономерности во взаимосвязанном
поведении временных рядов (13) для
одномерных
временных рядов вида (13), т. е. исследовать закономерности во взаимосвязанном
поведении временных рядов (13) для ![]() , характеризующих
динамику
, характеризующих
динамику ![]() переменных,
измеренных на каком-то одном (
переменных,
измеренных на каком-то одном ( ![]() -м) объекте,
то тогда говорят о статистическом анализе многомерного временного
ряда
-м) объекте,
то тогда говорят о статистическом анализе многомерного временного
ряда ![]()
![]() . По существу,
все задачи, связанные с анализом экономической динамики и прогнозом, предусматривают
использование в качестве своей статистической базы временных рядов
тех или иных показателей.
. По существу,
все задачи, связанные с анализом экономической динамики и прогнозом, предусматривают
использование в качестве своей статистической базы временных рядов
тех или иных показателей.
Как правило, в задачах бизнес-прогнозирования рассматриваются лишь дискретные
(по времени наблюдения) одномерные временные ряды для равноотстоящих
моментов наблюдения, т. е. ![]() где
где ![]() – заданный
временной такт (минута, час, сутки, неделя, месяц, квартал, год и т. п.).
В этих случаях исследуемый временной ряд нам будет удобнее представлять в виде
– заданный
временной такт (минута, час, сутки, неделя, месяц, квартал, год и т. п.).
В этих случаях исследуемый временной ряд нам будет удобнее представлять в виде
![]() (13’)
(13’)
где ![]() – значение
анализируемого показателя, зарегистрированное в
– значение
анализируемого показателя, зарегистрированное в ![]() -м такте времени
-м такте времени
![]() .
.
Говоря об использовании аппарата анализа временных рядов в проблеме прогнозирования, мы имеем в виду кратко- и среднесрочный прогноз, поскольку построение долгосрочного прогноза подразумевает обязательное использование методов организации и статистического анализа специальных экспертных оценок.
Генезис наблюдений, образующих временной ряд. Речь идет о структуре и классификации основных факторов, под воздействием которых формируются значения элементов временного ряда. Целесообразно выделить следующие 4 типа таких факторов.
(А) Долговременные, формирующие общую (в длительной перспективе)
тенденцию в изменении анализируемого признака ![]() . Обычно эта
тенденция описывается с помощью той или иной неслучайной функции f тр
(t), как правило, монотонной. Эту функцию называют функцией тренда
или просто трендом.
. Обычно эта
тенденция описывается с помощью той или иной неслучайной функции f тр
(t), как правило, монотонной. Эту функцию называют функцией тренда
или просто трендом.
(Б) Сезонные, формирующие периодически повторяющиеся в определенное
время года колебания анализируемого признака. Условимся обозначать результат
действия сезонных факторов с помощью неслучайной функции ![]() . Поскольку
эта функция должна быть периодической (с периодами, кратными сезонам,
т. е. кварталам), в ее аналитическом выражении участвуют гармоники (тригонометрические
функции), периодичность которых, как правило, обусловлена содержательной сущностью
задачи.
. Поскольку
эта функция должна быть периодической (с периодами, кратными сезонам,
т. е. кварталам), в ее аналитическом выражении участвуют гармоники (тригонометрические
функции), периодичность которых, как правило, обусловлена содержательной сущностью
задачи.
(В) Циклические (конъюнктурные), формирующие изменения
анализируемого признака, обусловленные действием долговременных циклов экономической,
демографической или астрофизической природы (волны Кондратьева, демографические
«ямы», циклы солнечной активности и т. п.). Результат действия циклических
факторов будем обозначать с помощью неслучайной функции ![]() .
.
(Г) Случайные (нерегулярные), не поддающиеся учету и регистрации.
Их воздействие на формирование значений временного ряда как раз и обусловливает
стохастическую природу элементов ![]() , а следовательно,
и необходимость интерпретации
, а следовательно,
и необходимость интерпретации ![]() как наблюдений,
произведенных над случайными величинами соответственно
как наблюдений,
произведенных над случайными величинами соответственно ![]() . Будем обозначать
результат воздействия случайных факторов с помощью случайных величин («остатков»,
«ошибок»)
. Будем обозначать
результат воздействия случайных факторов с помощью случайных величин («остатков»,
«ошибок») ![]() [1] . Конечно, вовсе не обязательно, чтобы в процессе формирования
значений всякого временного ряда участвовали одновременно факторы всех
четырех типов. В одних случаях значения временного ряда могут формироваться
под воздействием факторов (А), (Б) и (Г), в других – под воздействием
факторов (А), (В) и (Г) и, наконец, – исключительно под воздействием
одних только случайных факторов (Г). Однако во всех случаях предполагается
непременное участие случайных (эволюционных) факторов (Г).
Кроме того, как правило, принимается (в качестве гипотезы) аддитивная структурная
схема влияния факторов (А), (Б), (В) и (Г) на формирование значений
[1] . Конечно, вовсе не обязательно, чтобы в процессе формирования
значений всякого временного ряда участвовали одновременно факторы всех
четырех типов. В одних случаях значения временного ряда могут формироваться
под воздействием факторов (А), (Б) и (Г), в других – под воздействием
факторов (А), (В) и (Г) и, наконец, – исключительно под воздействием
одних только случайных факторов (Г). Однако во всех случаях предполагается
непременное участие случайных (эволюционных) факторов (Г).
Кроме того, как правило, принимается (в качестве гипотезы) аддитивная структурная
схема влияния факторов (А), (Б), (В) и (Г) на формирование значений
![]() , которая означает
правомерность представления значений членов временного ряда в виде разложения:
, которая означает
правомерность представления значений членов временного ряда в виде разложения:
![]() (14)
(14)
где ![]() а
а

Выводы о том, участвуют или нет факторы данного типа в формировании значений
![]() , могут базироваться
как на анализе содержательной сущности задачи (т. е. быть априорно-экспертными
по своей природе), так и на специальном статистическом анализе исследуемого
временного ряда.
, могут базироваться
как на анализе содержательной сущности задачи (т. е. быть априорно-экспертными
по своей природе), так и на специальном статистическом анализе исследуемого
временного ряда.
В рамках введенных понятий и обозначений задача статистического анализа временного ряда в общем виде может быть сформулирована следующим образом:
по результатам ![]() измерений
измерений
![]() исследуемой
переменной за
исследуемой
переменной за ![]() тактов времени
базового периода построить наилучшие (в определенном смысле) оценки
тактов времени
базового периода построить наилучшие (в определенном смысле) оценки ![]() для членов
разложения (14).
для членов
разложения (14).
Решение этой задачи используется для построения прогнозного значения
![]() на
на ![]() тактов времени
вперед с помощью формулы (14) при
тактов времени
вперед с помощью формулы (14) при ![]() и при подстановке
в нее полученных оценок компонентов правой части разложения.
и при подстановке
в нее полученных оценок компонентов правой части разложения.
Механизмы формирования и статистический анализ экспертных оценок
Обычно выделяются следующие основные типы организации работы группы экспертов ([6]):
· коллегиальный: «метод комиссий» (в виде открытой дискуссии по обсуждаемой проблеме); «метод суда» (в виде противостояния «защиты» и «обвинения» по каждому из вариантов обсуждаемого решения проблемы); «мозговая атака» и т.п.;
· частично коллегиальный: сценарный анализ типа «что – если», метод «Делфи» – многотуровое обсуждение проблемы с тайным голосованием экспертов или заполнением специальных анонимных анкет в конце каждого тура и работой независимой аналитической группы в промежутках между турами и т.п.;
· индивидуально-автономный: каждый из участников экспертной группы формирует и высказывает свое мнение (независимо от позиций других участников) в виде ранжирования обсуждаемых вариантов решения (или объектов), их парных сравнений или отнесения каждого из них к одной из заранее описанных градаций (см. формы представления исходных статистических данных в виде таблиц частот или таблиц сопряженности в п. 1). Иногда эксперты должны оценивать вероятность наступления того или иного события.
При любом из упомянутых выше типов организации работы экспертов приходится проводить статистический анализ экспертных мнений. К основным задачам статистического анализа экспертных оценок относятся:
(i) Исследование структуры совокупности экспертных мнений. Эта задача
решается средствами многомерного статистического анализа – методами ранговой
корреляции, кластер-анализа, многомерного шкалирования и т.п. (см. [1], гл.
12, 13]. Так, если ответы экспертов ![]() и
и ![]() даны в виде
упорядочений
даны в виде
упорядочений ![]() сравниваемых
вариантов решения (или объектов) соответственно
сравниваемых
вариантов решения (или объектов) соответственно ![]() и
и ![]() , то «расстояние»
, то «расстояние»
![]() между мнениями
между мнениями
![]() -го и
-го и
![]() -го экспертов
измеряют величиной
-го экспертов
измеряют величиной ![]() , где
, где
![]() – коэффициент
ранговой корреляции Спирмена (см. [1], гл. 11]). Определив тот или иной способ
вычисления «расстояния» между мнениями пары экспертов, мы можем решать затем
задачу «кластеризации» экспертов, интерпретируя каждый из найденных таким образом
кластер как группу экспертов-единомышленников.
– коэффициент
ранговой корреляции Спирмена (см. [1], гл. 11]). Определив тот или иной способ
вычисления «расстояния» между мнениями пары экспертов, мы можем решать затем
задачу «кластеризации» экспертов, интерпретируя каждый из найденных таким образом
кластер как группу экспертов-единомышленников.
(ii) Анализ взаимной согласованности мнений группы экспертов. Располагая мнениями целой группы экспертов, аналитик-статистик стремится оценить степень согласованности всех этих экспертных оценок, в том числе и статистически проверить гипотезу о полном отсутствии какой-либо их согласованности (и тогда, очевидно, следует либо уточнить постановку предложенной экспертам задачи, либо поменять состав экспертной группы). Эта задача также решается средствами многомерного статистического анализа. Выбор конкретного метода зависит от формы исходных статистических данных. Например, если мнения экспертов представлены ранжировками, то в качестве меры их согласованности можно рассматривать коэффициент конкордации Кендалла:
![]() .
.
Близость величины ![]() к единице свидетельствует
о высокой степени согласованности анализируемых мнений (при
к единице свидетельствует
о высокой степени согласованности анализируемых мнений (при ![]() все мнения
просто совпадают). Малые значения
все мнения
просто совпадают). Малые значения ![]() говорят об
отсутствии какой бы то ни было согласованности в анализируемых мнениях (существует
строгий статистический критерий проверки этой гипотезы (см. [1, гл. 11]).
говорят об
отсутствии какой бы то ни было согласованности в анализируемых мнениях (существует
строгий статистический критерий проверки этой гипотезы (см. [1, гл. 11]).
(iii) Построение единого группового мнения и оценка относительной компетентности
каждого эксперта. Поиск единого группового мнения сводится к решению соответствующей
оптимизационной задачи. Так, например, при балльных экспертных оценках
![]() анализируемых
вариантов решения (или
анализируемых
вариантов решения (или ![]() объектов),
т.е. при исходных статистических данных вида
объектов),
т.е. при исходных статистических данных вида
![]()
где ![]() – балльная
оценка
– балльная
оценка ![]() -го объекта
(варианта решения), данная
-го объекта
(варианта решения), данная ![]() -м экспертом,
единое групповое мнение
-м экспертом,
единое групповое мнение ![]() является решением
оптимизационной задачи вида
является решением
оптимизационной задачи вида
![]()
![]() ,
,
где с помощью ![]() обозначается
решение оптимизационной задачи вида
обозначается
решение оптимизационной задачи вида ![]()
![]() , т.е.
, т.е.
![]() .
.
Если же исходные данные представлены в виде ранжировок (9), то единая групповая
ранжировка ![]() определяется
как решение оптимизационной задачи вида
определяется
как решение оптимизационной задачи вида
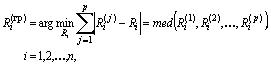
где с помощью ![]() обозначена
медиана ряда
обозначена
медиана ряда ![]() , т.е. средняя
по расположению величина
, т.е. средняя
по расположению величина ![]() , когда члены
этого ряда расположены в порядке возрастания их величин.
, когда члены
этого ряда расположены в порядке возрастания их величин.
Наконец, при задании мнения j-го эксперта в виде матрицы парных сравнений
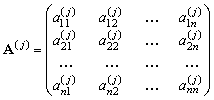
элементы матрицы парных сравнений ![]() группового
мнения
группового
мнения ![]() подбираются
таким образом, чтобы
подбираются
таким образом, чтобы
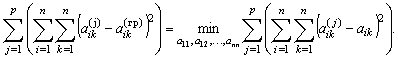
Основная идея различных подходов к оценке относительной компетентности каждого (j-го) эксперта, заключается в следующем: чем «дальше» мнение j-го эксперта отстоит от единого группового мнения, тем ниже оценивается уровень его относительной компетентности. Заметим, что если в результате исследования структуры совокупности экспертных мнений аналитик-статистик приходит к выводу о наличии нескольких подгрупп экспертов с однородностью мнений внутри каждой подгруппы и с существенным различием мнений в любой паре таких подгрупп, то задача единого группового мнения и оценка относительной компетентности эксперта решается отдельно для каждой из выявленных подгрупп.
[1] Случайные факторы, в свою очередь, могут быть двоякой природы: внезапными («разладочными»), приводящими к скачкообразным структурным изменениям в механизме формирования значений x(t) (что выражается, например, в радикальных скачкообразных изменениях основных структурных характеристик функций f тр (t), j(t) и y(t) анализируемого временного ряда в случайный момент времени), и эволюционными остаточными, обусловливающими относительно небольшие случайные отклонения значений x(t) от тех, которые должны были бы получиться только под воздействием факторов (А), (Б) и (В). Однако в данном разделе будут рассмотрены схемы формирования временных рядов, включающие в себя действие только эволюционных остаточных случайных факторов.
| Предыдущая |