

СТРАТЕГИИ БИЗНЕСА: АНАЛИТИЧЕСКИЙ СПРАВОЧНИК
Под общей редакцией академика РАЕН, д.э.н. Г.Б.
Клейнера
Москва, «КОНСЭКО»,1998
| Предыдущая |
Приложение 1. МЕТОДЫ СТАТИСТИЧЕСКОГО АНАЛИЗА И ПРОГНОЗИРОВАНИЯ В БИЗНЕСЕ
Приводимый ниже материал нетрадиционен для руководств по бизнесу. Не вдаваясь в полемику о том, нужны ли современному бизнесмену или управляющему знания об инструментах и методах прогнозирования или достаточно опираться на интуицию и опыт, отметим, что в силу сложившихся в России условий значительная часть бизнесменов получила техническое образование и в принципе вполне подготовлена к восприятию минимума, необходимого для понимания методов статистического анализа и прогнозирования. Данное приложение поможет читателю извлечь сведения о типах и источниках исходных данных, используемых для прогнозирования и анализа бизнеса, познакомиться с классификацией методов и моделей статистического анализа, а также с примерами применения методов для прогнозирования количественных и качественных характеристик предприятия и его среды.
1. Исходные данные для статистического анализа и прогнозирования
Поскольку в этом приложении речь идет о статистическом анализе и прогнозировании в бизнесе (в связи с общей проблемой выработки стратегии), кратко остановимся на сущности обоих этих понятий.
Статистический анализ исследуемого явления или процесса всегда опирается на исходные статистические данные. Выводы статистического анализа составляют существенный компонент системы поддержки принятия стратегических решения. Форма и содержание исходных статистических данных зависят от конечных прикладных целей исследования и используемых источников (см. ниже п.3.). В частности, конечные прикладные цели статистического анализа механизма функционирования фирм (предприятий) и связанных с этим задач прогнозирования обусловливают состав и структуру показателей (так называемое фазовое пространство), наблюдение за которыми и образует массив исходных статистических данных. Пример структуры этого фазового пространства для анализа состояния стратегических аспектов бизнеса представлен в табл. 1
Таблица 1. Вариант системы показателей стратегического анализа деятельности предприятия
|
Состояние |
Поведение (управляемые или частично управляемые параметры) |
Результат |
Внешняя среда (гео-социо- экономико-демографические характеристики) |
|
Юридическая форма и статус фирмы Направление деятельности Число работников Основные фонды Занимаемая площадь (количество, качество) Уровень технической и информационной обеспеченности Возраст фирмы Уровень квалификации сотрудников* Моральный климат* |
Вложения в развитие основных фондов (в долях от оборота) Вложения в службы маркетинга (в долях от оборота) Характеристики системы материального стимулирования сотрудников Доля оборота, приходящаяся на самого крупного заказчика Доля поставок, приходящаяся на самого крупного поставщика Характеристики участия в спонсорской и благотворительной деятельности |
Объем продаж Оборот Прибыль Соотношение быстрых активов и текущих пассивов Задержки платежей Другие конфликтные ситуации Соотношение прибыли и процентных ставок Репутация фирмы («Goodwill»)* |
Социо-демогра-фические характеристики потенциальных клиентов Экономические характеристики клиентов Макрохаракте-ристики общей экономической ситуации Характеристики конкурентной среды (число и рейтинг подобных фирм и т.п.) Характеристики фактических и потенциальных поставщиков Инвестиционная привлекательность данного направления деятельности в регионе расположения фирмы |
* Данные показатели оцениваются экспертами
Прогнозирование заключается в основанном на соответствующем статистическом анализе описании состояния изучаемой системы или процесса через один, два или большее число тактов времени по отношению к текущему моменту времени, т.е. к настоящему. Следует отличать прогноз от предсказания. Прогноз обладает свойством научного результата. Другими словами, в его основе лежит научное обоснование, которое может быть воспроизведено и без автора прогноза. Предсказание же порождается другими инструментами – интуицией, экстрасенсорными способностями, магией, наконец. Оно воспринимается на веру, как данность. Экспертная оценка, т.е. прогноз специалиста в данной конкретной области, представляет собой некоторый промежуточный (между прогнозированием и предсказанием) вариант подхода к формированию представления о будущем. С одной стороны, эта оценка основана на субъективном представлении эксперта о возможном развитии прогнозируемого процесса, с другой, – она учитывает многие факторы, если и не поддающиеся непосредственному измерению и формализации, то допускающие объективную интерпретацию в рамках научного обоснования эксперта. Поэтому организацию и статистический анализ экспертных оценок обычно включают в состав математического инструментария прогнозирования (см. ниже п. 3.).
Статистические методы анализа и прогнозирования основаны обычно на глубокой обработке статистических данных, относящихся к изучаемому процессу.
1. Основные источники исходных статистических данных делят на первичные и вторичные.
К первичным источникам относят специальные выборочные обследования, опросы, переписи, направленные на получение тех данных и в такой форме, которые необходимы именно для запланированных прогнозных расчетов или управленческих решений. Получение исходных статистических данных из первичных источников связано со специально спланированной работой (и соответственно с выделением для этого специальных средств). Планируется состав показателей, способ организации выборки (о различных способах организации выборки см., например, [1] и гл. 6), а иногда – и фиксированные значения некоторых показателей, при которых производится регистрация значений остальных показателей. Основными респондентами (объектами выборочных обследований) при обращении к первичным источникам являются все или определенные категории потенциальных клиентов (потребителей продукции) фирмы, ее поставщики, служащие, наконец, общество в целом.
Говоря о видах специальных обследований, надо выделить: обследования по
времени— одномоментные и периодически повторяющиеся; по охвату респондентов
– сплошные и выборочные; по способам– очные интервью и анкетирование,
почтовая рассылка анкет или вопросников или их публикация в прессе, телефонные
интервью (последние два способа, конечно, дешевле первого, однако дают, как
правило, смещенные результаты: по почте отвечает от 10% до 50% от общего числа
респондентов, причем, что самое главное, – лишь их вполне определенные социо-демографические
типы; при отсутствии сплошной телефонизации телефонные интервью не могут
обеспечить представительной выборки). При организации специальных статистических
обследований прогнозист обязан иметь четкие ответы на следующие вопросы:
- к кому именно обращены вопросы (т.е. определить «единицу» статистического
обследования) и с какой целью;
- как должны быть сформулированы вопросы (т.е. определить конкретную форму анкеты
или опросного листа);
- сколько респондентов должно быть включено в обследование (т.е. определить
объем выборки, необходимый для достижения заданной точности выводов);
- как именно следует отбирать респондентов для включения их в обследуемую выборку.
Вторичные источники – это опубликованные в том или ином виде исходные данные, уже собранные кем-то вне прямой связи с конкретной задачей прогнозиста, но доставляющие информацию, в той или иной мере полезную именно для решения этой конкретной задачи.
В российских условиях к таким источникам следует отнести, в первую очередь, различные издания Госкомстата РФ, а также ряд специализированных деловых периодических изданий: журналы «Эксперт», «Коммерсант», «Финансовые рынки», финансовые приложения «Известий», «Экономика и жизнь» и т.п. Сюда же можно отнести и ряд созданных за последние годы специализированных коммерческих баз данных по фирмам, предприятиям, регионам.
Очевидно, первичные источники предоставляют в распоряжение прогнозиста и аналитика исходные статистические данные более высокого порядка по предъявляемым к ним критериям, чем вторичные. Однако они и стоят существенно дороже.
2. Требования, предъявляемые к исходным статистическим данным. Формируя массив исходных статистических данных из первичных или вторичных источников, следует помнить об основных требованиях к качеству этих данных.
(i) Релевантность. Это свойство означает, что используемые данные (т.е. выбранные для анализа переменные, методология и время их измерения) должны отражать именно анализируемые стороны деловой деятельности и должны быть «привязаны» к нужным объектам и соответствующим моментам времени.
(ii) Надежность и точность. Это свойство исходных данных достигается с помощью различных (прямых и косвенных) методов проверки надежности используемых источников, соблюдения принятой методологии измерений, достоверности ответов респондентов, вылавливания сбоев и опечаток в их записи.
(iii) Сопоставимость. Сами данные должны сопровождаться такими комментариями и пояснениями, касающимися смысла анализируемых показателей и методологии их измерения, которые позволили бы сохранить возможность их сопоставления (во времени и пространстве) и «приведения к общему знаменателю» в ситуациях, характеризующихся изменениями в методологии измерений и корректировкой состава анализируемых переменных.
(iv) Представительность (репрезентативность). Соблюдение этого свойства достигается таким способом организации выборки, при котором она полно и адекватно представляет изучаемые свойства всей анализируемой совокупности (т.е. той совокупности, от которой эта выборка отбиралась). Наиболее распространенными способами отбора респондентов в выборку, обеспечивающими ее репрезентативность, являются простой случайный, расслоенный случайный, систематический, одноступенчатый гнездовой и др. (подробное описание различных способов организации выборки можно найти, например, в работе [2]). Так, если нас интересует распределение потенциальных клиентов по величине среднедушевого дохода, то мы должны обеспечить наличие в контрольной выборке пропорционального представительства всех социально-экономических слоев населения анализируемого региона, что будет достигнуто с помощью правильно организованного расслоенного случайного отбора. К сожалению, приходится достаточно часто сталкиваться с нарушениями этого важнейшего требования даже в традиционной практике выборочных обследований Госкомстата РФ.
3. Основные типы исходных данных. Речь идет о той форме представления исходных данных, в которой они подаются на «вход» статистического анализа и процедуры прогнозирования анализируемых показателей.
Динамическая таблица «объект–свойство» (панельные данные) является наиболее общим типом представления исходных данных. Для пространства показателей, приведенного в табл. 1, динамическая таблица «объект–свойство» может быть представлена в виде временной последовательности матриц
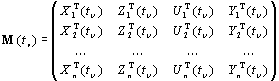 , (1)
, (1)
![]() ,
,
где ![]() – векторы-строки
значений соответственно поведенческих, статусных, внешних (гео-социо-экономико-демографических)
и результирующих показателей, характеризующих
– векторы-строки
значений соответственно поведенческих, статусных, внешних (гео-социо-экономико-демографических)
и результирующих показателей, характеризующих ![]() -ю обследованную
фирму (компанию, предприятие) в
-ю обследованную
фирму (компанию, предприятие) в ![]() -й временной
такт, а внешний индекс Т означает операцию транспонирования вектора или матрицы.
Очевидно, количество строк матриц
-й временной
такт, а внешний индекс Т означает операцию транспонирования вектора или матрицы.
Очевидно, количество строк матриц ![]() будет определяться
числом статистически обследованных фирм
будет определяться
числом статистически обследованных фирм ![]() , а число столбцов
– общим числом анализируемых показателей
, а число столбцов
– общим числом анализируемых показателей ![]() (под p,
k, l и m подразумеваются количества, соответственно,поведенчских,
статусных, внешнихи результирующих показателей). Наиболее распространенными
формами исходных данных являются два частных случая динамической таблицы «объект–свойство»
вида (1), а именно, статическая таблица «объект–свойство» и многомерный
временной ряд.
(под p,
k, l и m подразумеваются количества, соответственно,поведенчских,
статусных, внешнихи результирующих показателей). Наиболее распространенными
формами исходных данных являются два частных случая динамической таблицы «объект–свойство»
вида (1), а именно, статическая таблица «объект–свойство» и многомерный
временной ряд.
Статическая таблица «объект–свойство» (cross-section data) является частным случаем данных типа (1) при N = 1, т.е. она соответствует ситуациям, когда исходные данные регистрировались только «в пространстве», но не во времени. В этом случае вместо временнóй последовательности матриц (1) мы имеем единственный «временной срез» вида
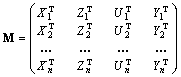 . (1’)
. (1’)
П р и м е р. В работе [3] приведены значения восьми
показателей (т.е. p + k + l + m = 8) для 266 крупных американских компаний
(n = 266). Соответственно матрица M вида (1'), представляющая
эти данные, будет иметь размерность ![]() . В качестве
анализируемых показателей были рассмотрены:
. В качестве
анализируемых показателей были рассмотрены:
x(1) – капитальные вложения за год (млн. долл.);
x(2) – годовой фонд оплаты труда (млн. долл.);
x(3) – расходы на нематериальные активы за год (млн. долл.);
x(4) – годовые расходы на рекламу и маркетинг (млн. долл.);
x(5) – годовые расходы на исследования и развитие (млн. долл.);
z – численность работников ( тыс. чел.);
y(1) – объем продаж за год ( млн. долл.);
y(2) – себестоимость проданного товара ( млн. долл.).
Многомерный временн¢ой ряд является частным случаем
данных типа (1) при n = 1. Это соответствует ситуации, когда регистрируются
значения анализируемых показателей только на одной фирме (компании, предприятии),
но в течение определенного числа ![]() тактов времени.
В данном случае исходные статистические данные будут представлены не временной
последовательностью матриц, а временной последовательностью набора
показателей:
тактов времени.
В данном случае исходные статистические данные будут представлены не временной
последовательностью матриц, а временной последовательностью набора
показателей:
![]() , (1’’)
, (1’’)
![]() .
.
П р и м е р. Для определения оптимальной площади выставочных полок (x кв. футов), выделяемой магазином для продажи книг, в течение 11 недель регистрировались значения x(t) и y(t), где y(t) – количество книг, проданных в течение t-й недели t = 1, 2, … 11. Соответственно в качестве исходных данных имеем последовательность из одиннадцати пар чисел (x(t), y(t)), t = 1, 2, … n.
Частоты и таблицы сопряженности. До сих пор, говоря о переменных анализируемого «фазового пространства» показателей, мы имели в виду так называемые количественные признаки, т.е. такие переменные, которые позволяют измерять степень проявления анализируемого свойства статистически обследуемой фирмы в определенной числовой шкале (в денежных единицах, штуках, квадратных футах и т.п.). Однако среди анализируемых признаков встречаются и неколичественные (качественные, категоризованные) переменные, т.е. такие переменные, которые позволяют только разбивать статистически обследуемые объекты на однородные по анализируемому свойству классы. Из признаков, представленных в табл. 1, к качественным переменным относятся, например, юридическая форма и статус фирмы, направление ее деятельности, моральный климат, уровень ее репутации («goodwill») и т.п. Если в результате измерения качественной переменной однородные классы поддаются упорядочению (по степени проявления анализируемого свойства), то такая качественная переменная называется ординальной (моральный климат на фирме, уровень ее репутации). Если однородные классы не поддаются упорядочению по данному свойству (юридическая форма, направление деятельности), то соответствующая переменная называется номинальной. Возможные «значения» качественной переменной, т.е. классы, к которым может быть отнесен статистически обследованный объект по анализируемой качественной переменной, называются градациями (или категориями) этой переменной.
Формально исходные статистические данные для качественных переменных также
могут быть представлены в виде (1). При этом под ![]() следует понимать
номер градации, к которой отнесен объект i по свойству j
в ν-й такт времени. Однако на практике, как правило, используется
другая («частотная») форма представления качественных данных. А именно:
следует понимать
номер градации, к которой отнесен объект i по свойству j
в ν-й такт времени. Однако на практике, как правило, используется
другая («частотная») форма представления качественных данных. А именно:
если анализируется единственная качественная переменная x, имеющая s возможных значений, то результаты наблюдений n объектов по этой переменной представляются в виде таблицы частот (табл. 2).
Таблица 2
|
Число объектов, отнесенных к j-й градации |
Градации анализируемой переменной |
|
|||||
|
1 |
2 |
... |
|
... |
|
||
|
1 |
|
|
... |
|
... |
|
|
если анализируется пара качественных переменных (x, y), в которой
переменная ![]() имеет
имеет
![]() градаций, а
переменная
градаций, а
переменная ![]() имеет
имеет
![]() градаций, то
результаты наблюдений
градаций, то
результаты наблюдений ![]() объектов по
этой паре переменных представляются в виде таблицы сопряженности (табл.
3):
объектов по
этой паре переменных представляются в виде таблицы сопряженности (табл.
3):
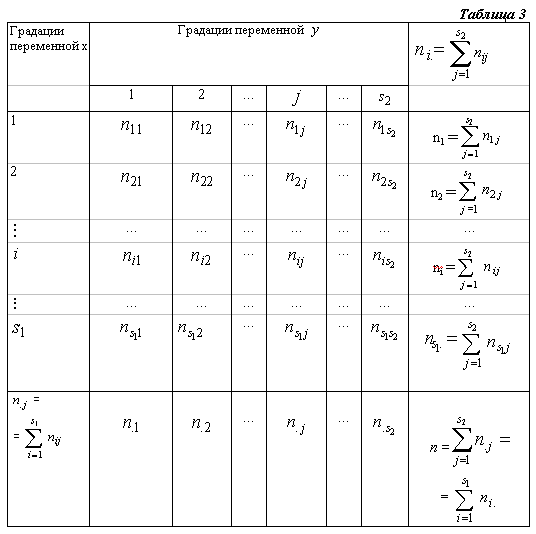
В этой таблице частоты nij определяют число тех статистически обследованных объектов (из общего числа n), которые по переменной x были отнесены к градации i, а по переменной y – к градации j.
При одновременном анализе трех и большего числа качественных переменных исходные статистические данные представляются в виде соответственно трехвходовых и многовходовых таблиц сопряженности, которые формируются аналогичным образом.
Следующие две формы представления исходных данных используются в ситуациях, когда источниками этих данных являются эксперты.
Ранжировки (рейтинги, упорядочения). Предположим, речь идет о таких показателях как уровень квалификации сотрудников (оцениваемый объект – сотрудник фирмы), моральный климат в фирме или ее репутация (оцениваемый объект – фирма). Измерение этих показателей осуществляется, как правило, с помощью экспертов и одной из распространенных форм ответов эксперта является упорядочение оцениваемых объектов (в наших примерах – сотрудников фирмы или самих фирм) в порядке убывания их качества по анализируемому свойству. Таким образом, если i-й объект поставлен в этом ряду на 1-е место, то это означает, что он признан экспертом лучшим по анализируемому свойству в ряду из n оцениваемых объектов и ему приписывается 1-е место (или ранг Ri, равный единице).
Соответственно, если объекты оцениваются таким образом сразу по p свойствам (или по одному свойству, но с помощью p экспертов), то исходные статистические данные будут представлены матрицей рангов
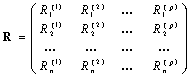 , (2)
, (2)
где ![]() – ранг, приписанный
экспертом i-му объекту по j-му свойству (или соответственно ранг,
приписанный j-м экспертом i-му объекту по анализируемому свойству).
– ранг, приписанный
экспертом i-му объекту по j-му свойству (или соответственно ранг,
приписанный j-м экспертом i-му объекту по анализируемому свойству).
Парные сравнения оцениваемых объектов по анализируемому свойству являются еще одной формой представления исходных статистических данных, когда в качестве их источников используются эксперты. В частности, с помощью экспертов формируют матрицу парных сравнений
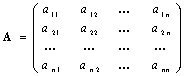 , (3)
, (3)
где aij равно 1, если i-й объект «не хуже» j-го, и равно 0 в противном случае.
Возможен более общий подход к интерпретации элементов aij, при котором под aij понимается вероятность того, что i-й объект не хуже j-го.
Таковы наиболее часто встречающиеся типы и формы представления исходных данных, используемых для статистического прогнозирования в бизнесе. Как правило, эти данные используются с помощью тех или иных правил преобразования, основанных на построении математической модели изучаемого процесса. Рассмотрим соответствующие понятия и приемы.
| Предыдущая |