

М.А. Боровская , С.В. Гриненко , Е.К. Задорожняя, Е.Л. Макарова, М.А. Масыч , М.В. Паничкина , А.А Ракитин, Е.А. Семерникова, И.А. Синявская , С.В. Соханевич
Мониторинг студентов и выпускников вуза как инструмент системы управления востребованностью молодых специалистов на рынке труда
| Предыдущая |
2.2. Инструментальные средства мониторинга: методический аспект
Составляющей информационного обеспечения является мониторинг – «технология сбора, накопления и обобщения информации для целей управления»[1]. Управление системой трудоустройства молодых специалистов вуза требует статистически достоверных данных о соотношении спроса и предложения по конкретным специальностям, отраслям и регионам, о требованиях работодателей к образованию, квалификации соискателей. В процессе сбора первичной информации о текущем состоянии и перспективах развития рынка труда находят применения различные инструментальные средства (рис. 2.2).
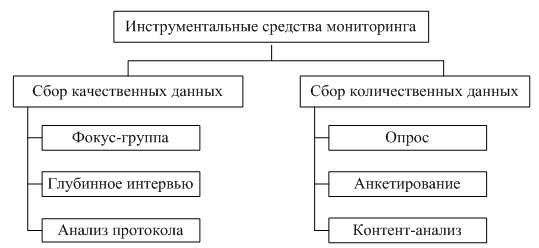
Рис. 2.2. Инструментальные средства мониторинга
Инструментарий сбора качественных данных позволяет получить подробные данные о мнениях, взглядах, отношениях очень небольшой группы лиц. Основные методы качественных исследований: фокус-группы, глубинные интервью, анализ протокола.
Фокус-группа представляет собой «групповое интервью, проводимое модератором в форме групповой дискуссии по заранее разработанному сценарию с небольшой группой «типичных» представителей изучаемой части населения, сходных по основным социальным характеристикам»[2]. Фокус-группа проходит в виде группового обсуждения интересующего исследователя вопроса; в ходе этого обсуждения участники группы, не скованные рамками стандартного интервью, могут свободно общаться друг с другом и выражать свои чувства и эмоции. В групповом обсуждении обычно участвует 6-12 человек. В течение полутора-трех часов подготовленный ведущий (модератор) руководит разговором, который проходит вполне свободно, но по конкретной схеме.
Интервью – «способ проведения социологических опросов как целенаправленной беседы интервьюера и опрашиваемого»[3]. «Искусство использования этого метода состоит в том, чтобы знать, о чем именно спрашивать, как спрашивать, какие задавать вопросы и, наконец, как убедиться в том, что можно верить полученным ответам»[4].
Интервью обычно применяется:
– на ранней стадии исследования для уточнения проблемы и составления программы;
– при опросе экспертов, специалистов, глубоко разбирающихся в том или ином вопросе;
– как наиболее гибкий метод, позволяющий учитывать особенности личности респондента.
Выделяют интервью трех классов[5]:
– глубинное интервью – «слабоструктурированная личная беседа интервьюера с респондентом в форме, побуждающей последнего к подробным ответам на задаваемые вопросы»[6]. Свободное интервью часто является начальным этапом разработки стандартизированного интервью или анкеты, проверкой приемлемости вопросов, информационной ёмкости ответов, а интервьюер выступает как исследователь. Перед началом серии интервью исследователь подготавливает план, в соответствии с которым будет проводиться интервью. В отличие от обычного опроса, план глубинного интервью представляет собой просто перечень вопросов, по которым интервьюер должен узнать мнение респондента. Интервью записывается на аудио и/или видеоаппаратуру для облегчения последующей расшифровки и анализа данных, а также для того, чтобы не потерять важную информацию. Далее аудио и/или видеозапись интервью подвергается обработке, в результате которой исследователь получает полный текст интервью. На основе данных текстов и впечатлений интервьюера составляется аналитический отчет.
– стандартизированные (формализованные) интервью по форме тождественно анкете, однако на содержание и форму вопросов существенно влияет специфика получения ответов – «лицом к лицу» с интервьюером.
– полустандартизированное интервью отличается от стандартизированного интервью по степени формализации анкеты: в анкете в перечне вариантов ответа включают вариант «Другое», что дает возможность респонденту предложить свой вариант ответа.
Интервью могут быть свободными (глубокие, клинические, фокусированные) и стандартизированными (формализованные). Свободное интервью носит характер длительной непринуждённой беседы, в которой вопросы интервьюера обусловлены конечной целью исследования. Свободное интервью часто является начальным этапом разработки стандартизированного интервью или анкеты, проверкой приемлемости вопросов, информационной ёмкости ответов, а интервьюер выступает как исследователь. Стандартизированное интервью по форме тождественно анкете, однако на содержание и форму вопросов существенно влияет специфика получения ответов – «лицом к лицу» с интервьюером. Анкетирование является менее дорогостоящим видом опроса, чем стандартизированное интервью, но социолог вынужден прибегать к последнему в тех случаях, когда опросу придаётся большое значение и существует сомнение в том, что все вопросы будут правильно поняты (например, переписи населения в некоторых районах проводятся методом стандартизированного интервью).
Основные преимущества метода интервью перед анкетированием состоят в следующем: возможность учета уровня культуры, образования, степени компетентности респондента и отслеживания реакции интервьюируемого, его отношения к проблеме и поставленным вопросам; выше точность результатов.
Метод анализа протокола подразумевает «погружение» респондента в конкретную ситуации и фиксацию его словесных описаний всех факторов и аргументов, которыми он руководствовался в процессе принятия решения. Иногда при применении данного метода используется диктофон. Затем исследователь анализирует протоколы, представленные респондентами[7].
Основные методы количественных исследований – различные виды опросов и контент-анализ. Опрос предполагает выяснение мнения респондента по определенному кругу включенных в анкету вопросов путем личного либо опосредованного контакта интервьюера с респондентом. К опросу также относится и анкетирование.
Экспертный опрос – методика, используемая для решения достаточно сложных проблем, требующих опроса высококвалифицированного специалиста, эксперта в определенной сфере. Эксперт – квалифицированный специалист в определенной области, привлекаемый для исследования, консультирования, выработки суждений, заключений, предложений, проведения экспертизы. В зависимости от целей исследования, экспертами могут выступать директора или собственники компаний, чиновники высокого ранга, экономические и политические обозреватели, высококлассные специалисты и др. Экспертный опрос проводится профессиональным интервьюером высокого уровня по заранее составленному сценарию обсуждения исследуемой темы. Беседа записывается на диктофон, а потом все записи, собранные в ходе экспертного опроса, расшифровываются и анализируются.
Анкетирование – одно из основных технических средств конкретного социального исследования; в процессе анкетирования каждому лицу из группы, выбранной для анкетирования, предлагается ответить письменно на вопросы, поставленные в форме опросного листа – анкеты. Анкетирование может проводиться тремя способами: анкета заполняется в присутствии интервьюера индивидуально; групповое заполнение в присутствии интервьюера; опрашиваемые самостоятельно заполняют и для сохранения анонимности одновременно сдают анкеты; «почтовое» анкетирование, когда анкета раздаётся или рассылается на дом, а затем опрошенным возвращается по почте. С целью повышения эффективности опроса перед массовым анкетированием, как правило, проводятся пробные опросы (50-100 анкет) для выбраковки неудачных («неработающих») вопросов.
Контент-анализ – количественный анализ вакансий и резюме, опубликованных в СМИ (газеты и журналы), государственных и муниципальных статистических сборников, обзоров кадровых агентств и консалтинговых компаний с целью последующей содержательной интерпретации выявленных закономерностей.
В отличие от качественных количественные методы исследования позволяют получить выраженную количественно информацию по ограниченному кругу проблем, но от большого числа людей. Данная информация уже может быть обработана методами статистического и математического анализа и предоставлена в форме графиков и таблиц. Обычно используют такие методы анализа количественных данных, как факторный и кластерный анализы, дисперсионный и конджойт-анализ. Рассмотрим такие часто используемые методы, как корреляционно-регрессионный и факторный анализы.
Регрессионный анализ – наиболее широко используемый метод многомерного статистического анализа. Термин «множественная регрессия» объясняется тем, что «анализу подвергается зависимость одного признака (результирующего) от набора независимых (факторных) признаков. Разделение признаков на результирующий и факторные осуществляется исследователем на основе содержательных представлений об изучаемом явлении (процессе). Все признаки должны быть количественными (хотя допускается и использование дихотомических признаков, принимающих лишь два значения, например 0 и 1)»[8].
Для корректного использования регрессионного анализа требуется выполнение определенных условий. Факторные признаки должны быть некоррелированы (отсутствие мультикол-линеарности), они предполагаются замеренными точно и в их измерениях нет автокорреляции, т.е. значения признаков у одного объекта не должны зависеть от значений признаков у других объектов. Чем сильнее степень разброса значений признака, тем больше значения дисперсии, среднеквадратического отклонения и коэффициента вариации. Число объектов должно превосходить число признаков в несколько раз, чтобы параметры уравнения множественной регрессии были статистически надежными. Исследуемая совокупность должна быть в достаточной мере качественно однородной. Существенные нарушения этих условий приводят к некорректному использованию моделей множественной регрессии.
При построении регрессионных моделей прежде всего возникает вопрос о виде функциональной зависимости, характеризующей взаимосвязи между результирующим признаком и несколькими признаками-факторами. Выбор формы связи должен основываться на качественном, теоретическом и логическом анализе сущности изучаемых явлений.
Чаще всего ограничиваются линейной регрессией, т.е. зависимостью вида
(2.1)
где Y – результирующий признак,
x1, …, xm – факторные признаки,
b1, …, bm – коэффициенты регрессии,
а – свободный член уравнения,
ε – «ошибка» модели.
Уравнение (2.1) является линейным по коэффициентам bj и в общем случае нелинейным по признакам Xj, где j=1, 2, …, m. Часто применяют логарифмическое преобразование (logX), использующееся, если наибольшее значение Х вдвое (или больше) превышает наименьшее при высокой корреляции между Х и Y (rXY>0,9). Если максимальное значение X в 20 или более раз превосходит минимальное, то это преобразование необходимо почти всегда[9].
В большинстве приложений регрессионной модели (2.1) признаки берут в исходном виде, т.е. уравнение (2.1) получается линейным и по признакам X1, ..., Xm. При использовании нелинейных преобразований исходных признаков регрессионную модель (2.1) нередко называют нелинейной регрессией.
Коэффициенты регрессии bj определяются таким образом, чтобы рассогласования ε, характеризующие степень приближения реальных значений результирующего признака Y с помощью линейной модели были минимальны. Это достигается на основе метода наименьших квадратов.
Если уравнение множественной регрессии (2.1) уже построено, то в вариации результирующего признака Y можно выделить часть, обусловленную изменениями факторных признаков, т.е. объясненную с помощью регрессионной модели, и остаточную, необъясненную часть. Очевидно, чем большую часть вариации признака Y объясняет уравнение регрессии, тем точнее по значениям факторных признаков можно восстановить значение результирующего, и, следовательно, тем теснее связь между ними. Естественной мерой тесноты этой связи служит отношение дисперсии признака Y, объясненной регрессионной моделью, к общей дисперсии признака Y:
(2.2)
Величина R называется коэффициентом множественной корреляции и определяет степень тесноты связи результирующего признака Y со всем набором факторных признаков X1, ..., Xm. В случае парной регрессии (т.е. при наличии всего одного фактора X1) совпадает с обычным коэффициентом парной корреляции rx,y. (Коэффициент корреляции rx,y – статистическая мера тесноты линейной связи пары признаков X и Y. Значения rx,y находятся в пределах [-1;+1]; чем ближе rx,y к ±1 , тем теснее связь данной пары признаков, тем ближе она к функциональной. Значения rx,y, близкие к нулю, указывают на отсутствие линейной связи признаков.) Чем ближе R2 к единице, тем точнее описывает уравнение регрессии (2.2) эмпирические данные.
В уравнении множественной линейной регрессии (2.1): величина bj – показывает, насколько в среднем изменяется результирующий признак Y при увеличении соответствующего фактора Xj на единицу шкалы его измерения при фиксированных (постоянных) значениях других факторов, входящих в уравнение регрессии (т.е. оценивается «чистое» воздействие каждого фактора на результат). Из этого определения следует, что коэффициенты регрессии bj непосредственно не сопоставимы между собой, так как зависят от единиц измерения факторов Xj. Чтобы сделать эти коэффициенты сопоставимыми, все признаки выражают в стандартизированном масштабе:
, (2.3)
где и – средние значения признаков Y и Xj,
σY и σXi – средние квадратичные отклонения признаков Y и Xi.
Уравнение множественной регрессии, построенное с использованием стандартизованных признаков, называется стандартизованным уравнением регрессии, а соответствующие коэффициенты регрессии – стандартизованными, или β (бэта) – коэффициентами. Между коэффициентами Вj и βi – существует простая связь:
. (2.4)
Стандартизованный коэффициент регрессии βi показывает, на сколько средних квадратичных отклонений σY изменяется Y при увеличении Xj – на одно среднеквадратическое отклонение , если остальные факторы, входящие в уравнение регрессии считать неизменными. Сопоставление факторов можно проводить и не на основе β – коэффициентов, а по их «вкладу» в объясненную дисперсию. В том случае, когда модель множественной регрессии строится для выборочной совокупности, необходимо проверять значимость коэффициентов регрессии Вj (с этой целью используется t-критерий Стьюдента), а также коэффициента множественной корреляции R (этой цели служит F-критерий Фишера). С помощью F-критерия осуществляется проверка достоверности и соблюдения условий, которым должна удовлетворять исходная информация в уравнении множественной регрессии.
Указанные критерии математической статистики используют и при изучении взаимосвязей признаков в генеральной совокупности. В этом случае проверяют, не вызвана ли выявленная статистическая закономерность стечением случайных обстоятельств, насколько она характерна для того комплекса условий, в которых находится обследуемая совокупность. Эта совокупность – не выборка из реальной генеральной совокупности, существование которой лишь предполагается. Имеющиеся данные рассматривают как выборку из некоторой гипотетической совокупности единиц, находящихся в тех же условиях. Гипотетическая совокупность является научной абстракцией. При интерпретации вероятностной оценки результатов сплошного наблюдения (оценки значимости и т.д.) надо учитывать, что в действительности никакой генеральной совокупности нет. Устанавливается не истинность полученного результата для какой-то более обширной генеральной совокупности, а степень его закономерности, свободы от случайных воздействий. Его широко используют на практике, в частности для отсева незначимых по t-статистике факторов[10]. Здесь необходимо отметить, что этот метод проверки существенности факторов заслуживает доверия лишь в тех случаях, когда признаки-факторы не коррелированны (или весьма слабо коррелированны), что зачастую невыполнимо на практике.
При построении уравнений множественной регрессии основным этапом является отбор наиболее существенных факторов, воздействующих на результирующий признак. Этот этап построения модели множественной регрессии производится на основе качественного, теоретического анализа в сочетании с использованием статистических приемов. Обычно отбор факторов проходит две стадии. На первой стадии, на основе содержательного анализа, намечают круг факторов, теоретически существенно влияющих на результирующий признак. На второй стадии качественный анализ дополняется количественными оценками, которые позволяют отобрать статистически существенные факторы для рассматриваемых конкретных условий реализации связи. Таких оценок существует довольно много. Они основаны на использовании парных или частных коэффициентов корреляции факторных признаков с результирующим признаком Y, t-критерия вкладов факторов в объясненную дисперсию и т.д.
Отбор факторов на второй стадии исследования начинают обычно с анализа матрицы парных коэффициентов корреляции признаков, полученных на первой стадии. Выявляются факторы, тесно связанные между собой . При наличии таких связей между факторными признаками один или несколько из них нужно исключить таким образом, чтобы между оставшимися факторами не было тесных связей (при этом коэффициенты корреляции между результирующим признаком Y и факторами могут быть, конечно, высокими). Эта процедура позволяет избежать отрицательных эффектов мультиколлинеарности. Затем можно использовать стратегию шагового отбора, реализованную в ряде алгоритмов пошаговой регрессии. Здесь получили распространение две схемы отбора.
Вторая схема пошаговой регрессии основана на последовательном исключении факторов с помощью t-критерия. Она заключается в том, что после построения уравнения регрессии и оценки значимости всех коэффициентов регрессии из модели исключают тот фактор, коэффициент при котором незначим и имеет наименьший коэффициент доверия t . После этого получают новое уравнение множественной регрессии и снова производят оценку значимости всех оставшихся коэффициентов регрессии. Если среди них опять окажутся незначимые, то опять исключают фактор с наименьшим значением t-критерия. Процесс исключения факторов останавливается на том шаге, при котором все регрессионные коэффициенты значимы. При использовании этой схемы пошаговой регрессии следует иметь в виду те особенности применения t-критерия, о которых шла речь выше (в частности, негативные последствия мультиколлинеарности).
Характеризуя в целом последствия мультиколлинеарности, отметим, что при ее наличии снижается точность оценок регрессионных коэффициентов (стандартные ошибки коэффициентов получаются слишком большими); становится невозможной оценка статистической значимости коэффициентов регрессии с помощью t-критерия, отсюда вероятно некорректное введение в анализ тех или иных переменных; резко возрастает чувствительность коэффициентов регрессии к особенностям исходных данных, так что добавление, например, небольшого числа наблюдений может привести к сильным сдвигам в значениях βi.
При отсутствии мультиколлинеарности и выполнении остальных требований (они перечислены выше) модель множественной регрессии позволяет оценить значимость каждого из рассматриваемых факторов, определить степень существенности воздействия каждого фактора на результат (разные аспекты этой существенности проявляются в значениях β – коэффициентов и вкладов факторов, получаемых из пошаговой схемы), получить количественную оценку величины средних изменений результирующего признака при изменениях каждого из факторов (значения регрессионных коэффициентов Вj). Наконец, величина коэффициента множественной корреляции R дает оценку веса учтенных факторов в объяснении вариаций результирующего признака Y (и соответственно оценку веса неучтенных факторов).
Многомерное шкалирование (МШ) – одно из направлений анализа данных; оно отличается от других методов статистического анализа, прежде всего видом исходных данных, которые в данном случае представляют собой матрицу близости между парами объектов («близость», или «сходство», объектов можно определять различными способами)[11]. Цель МШ – это описание матрицы близости в терминах расстояний между точками, представление данных о сходстве объектов в виде системы точек в пространстве малой размерности (например, на двумерной плоскости). Упрощая, можно сказать, что «на вход» методов МШ подается матрица близости, а «на выходе» получается координатное смещение точек[12].
Основное предположение МШ заключается в том, что существует некоторое метрическое пространство существенных базовых характеристик, которые неявно и послужили основой для полученных эмпирических данных о близости между парами объектов. Следовательно, объекты можно представить как точки в этом пространстве. Предполагают также, что более близким (по исходной матрице) объектам соответствуют меньшие расстояния в пространстве базовых характеристик. Таким образом, многомерное шкалирование – это совокупность методов анализа эмпирических данных о близости объектов, с помощью которых определяется размерность пространства существенных для данной содержательной задачи характеристик измеряемых объектов и конструируется конфигурация точек (объектов) в этом пространстве. Это пространство (многомерная шкала) аналогично обычно используемым шкалам в том смысле, что значениям существенных характеристик измеряемых объектов соответствуют определенные позиции на осях пространства.
Данные в исходной матрице близости объектов могут быть получены различными способами. Вообще говоря, методы МШ ориентируются на экспертные оценки близости объектов, когда респонденту предъявляют пары объектов, и он должен упорядочить их по степени внутреннего сходства, которое иногда оценивается в баллах. Если данные о близости пар объектов не получены непосредственно, а рассчитаны на основании других данных (различные коэффициенты связи), то следует иметь в виду, что МШ может оказаться далеко не лучшим способом анализа структуры исходных данных. Действительно, первичные данные, на основе которых рассчитывались близости, содержат больше информации, чем «вторичные» данные о близости. Матрица близости должна удовлетворять определенным естественным условиям.
Методы МШ делятся обычно на две категории: неметрическое МШ (НМШ) и метрическое МШ (ММЩ). Методы ММШ используют, когда оценки близости получены на количественной шкале (не ниже интервальной). В таком виде в исследованиях социальных проблем оценки близости возникают крайне редко. Более естественной является оценка близости, измеренная на порядковой шкале (когда пары объектов можно только упорядочить по степени схожести объектов). В этом случае используют методы НМШ, которые дают "покоординатную развертку" матрицы близости в пространстве двух-трех существенных характеристик, так что упорядочения объектов по матрице близости расстояниям в этом пространстве совпадают [13].
Среди основных возможностей методов многомерного шкалирования выделяют:
– построение метрического пространства невысокой размерности, в котором наилучшим образом сохраняется структура исходных данных о близости пар объектов. Проектирование объектов на оси полученного пространства определяет их положение на этих осях, т.е. производится процесс шкалирования.
– визуализация структуры исходных данных в виде конфигурации точек (объектов) в двух-трехмерном базовом пространстве.
– интерпретация полученных осей (базовых характеристик) и конфигурации объектов – конечный результат применения МШ, дающий новое знание об изучаемой структуре (в случае корректного использования метода на всех этапах). Характер конфигурации объектов, а также «внешние» по отношению к исходным данным сведения позволяют дать содержательную интерпретацию осям и тем самым выявить «глубинные» мотивы, которыми руководствовались эксперты, упорядочивая пары объектов по степени их близости (в одном случае), или обнаружить «скрытые» факторы, определяющие структуру сходства и различия объектов (в другом случае).
Для методов МШ, как и для других методов анализа данных, слабо разработаны вероятностные модели и аппарат статистического оценивания.
Для повышения достоверности получаемых с помощью методов МШ результатов в одном исследовании нередко используют разные методы МШ; кроме того, эти методы применяют совместно с другими методами статанализа; кластер-анализом, факторным анализом, множественной регрессией.
При использовании регрессионного анализа акцент делается на выявлении веса каждого факторного признака, воздействующего на результат, на «количественную оценку чистого воздействия данного фактора при элиминировании остальных»[14]. Существует и другой подход к исследованию структуры взаимодействия признаков, развивающийся в рамках факторного анализа. Этот подход основан на представлении о комплексном характере изучаемого явления, выражающемся, в частности, во взаимосвязях и взаимообусловленности отдельных признаков. Акцент в факторном анализе делается на исследовании внутренних причин, формирующих специфику изучаемого явления, на выявлении обобщенных факторов, которые стоят за соответствующими конкретными показателями.
Факторный анализ – «метод многомерного статистического анализа, позволяющий на основе экспериментального наблюдения признаков объекта выделить группу переменных, определяющих корреляционную взаимосвязь между признаками»[15]. Суть факторного анализа – на основе исследования корреляционных взаимосвязей признаков находить причины, определяющие эти взаимосвязи. Выделяют четыре типовые задачи факторного анализа[16]:
1) оценка влияния относительного изменения факторов на относительное изменение результативного показателя;
2) оценка влияния абсолютного изменения i-го фактора на абсолютное изменение результативного показателя;
3) определение отношения величины изменения результативного показателя, вызванного изменением i-го фактора, к базовой величине результативного показателя;
4) определение доли абсолютного изменения результативного показателя, вызванного изменением i-го фактора, в общем изменении результативного показателя.
При этом проведение факторного анализа требует выполнения следующих процедур[17]:
– построение экономически обоснованной факторной модели;
– выбор приема факторного анализа и подготовка условий для его выполнения;
– реализация счетных процедур анализа модели;
– формулирование выводов и рекомендаций по результатам анализа.
Первый этап особенно важен, так как неправильно построенная модель может привести к логически неоправданным результатам. Смысл этого этапа состоит в следующем: любое расширение жестко детерминированной факторной модели не должно противоречить логике связи «причина – следствие». В общем случае моделью описываемой взаимосвязи является набор линейных уравнений. Коэффициентами этих уравнений являются так называемые нагрузки, которые показывают «вес» каждого из факторов для данного признака. В матричном виде эта система уравнений может быть записана как[18]:
X = S*F + E, (2.5)
где X – матрица признаков (или переменных),
S – матрица нагрузок,
F – матрица новых – «латентных» – переменных,
E – матрица остатков.
Это уравнение, по сути, описывает переход от первичных переменных (признаков) к новым переменным (факторам). Такое преобразование позволяет:
– выделить переменные, определяющие исследуемый набор признаков, проанализировать их число и природу;
– сжать данные – вместо большого объема переменных система полностью описывается несколькими факторами.
Существует четыре типа факторных моделей анализа[19] :
– аддитивная модель, т. е. модель, в которую факторы входят в виде алгебраической суммы;
– мультипликативная модель, т. е. модель, в которую факторы входят в виде произведения;
– кратная модель, т. е. модель, представляющая собой отношение факторов;
– смешанная модель, т. е. модель, в которую факторы входят в различных комбинациях.
На втором этапе выбирается один из приемов факторного анализа: выявления изолированного влияния факторов, интегральный, цепных подстановок, абсолютных разниц, относительных разниц, пропорционального деления, логарифмирования главных компонент (principal component analysis, PCA) и разложение по сингулярным значениям (singular value decomposition, SVD), центроидный и др [20], . Первые три способа основываются на методе элиминирования. Элиминировать – «значит устранить, отклонить, исключить воздействие всех факторов на величину результативного показателя, кроме одного»[22]. Этот метод исходит из того, что все факторы изменяются независимо друг от друга: сначала изменяется один, а все другие остаются без изменения, потом изменяются два, затем три и т. д., при неизменности остальных. Это позволяет определить влияние каждого фактора на величину исследуемого показателя в отдельности. Рассмотрим некоторые приемы в отдельности.
Прием цепной подстановки является весьма простым и наглядным методом, наиболее универсальным из всех. Он используется для расчета влияния факторов во всех типах детерминированных факторных моделей: аддитивных, мультипликативных, кратных и смешанных. Этот способ позволяет определить влияние отдельных факторов на изменение величины результативного показателя путем постепенной замены базисной величины каждого факторного показателя в объеме результативного показателя на фактическую в отчетном периоде. С этой целью определяют ряд условных величин результативного показателя, которые учитывают изменение одного, затем двух, затем трех и т. д. факторов, допуская, что остальные не меняются. Сравнение величины результативного показателя до и после изменения уровня того или иного фактора позволяет определить воздействие конкретного фактора на прирост результативного показателя, исключив влияние остальных факторов. При использовании этого метода достигается полное разложение. Большое значение имеет очередность изменения значений факторов, так как от этого зависит количественная оценка влияния каждого фактора.
Единой методики определения очередности изменения значений факторов не существует, и существовать не может – в некоторых моделях эта очередность произвольная. Лишь для небольшого числа моделей можно использовать формализованные подходы. На практике эта проблема не имеет большого значения, поскольку в ретроспективном анализе важны тенденции и относительная значимость того или иного фактора, а не точные оценки их влияния. Тем не менее для соблюдения более или менее единого подхода к определению очередности замены факторов в модели можно сформулировать общие принципы, а именно:
– признак, непосредственно относящийся к изучаемому явлению и характеризующий его количественную сторону, называется первичным или количественным. Эти признаки: а) абсолютные (объемные); б) их можно суммировать в пространстве и времени;
– признаки, относящиеся к изучаемому явлению не непосредственно, а через один или несколько других признаков и характеризующие качественную сторону изучаемого явления, называются вторичными или качественными. Эти признаки: а) относительные; б) их нельзя суммировать в пространстве и времени;
– в полной двухфакторной модели один фактор всегда количественный, второй – качественный. В этом случае рекомендуют начинать с количественного показателя. Если же имеется несколько количественных и несколько качественных показателей, то сначала следует изменить величину факторов первого уровня подчинения, а потом более низкого. Таким образом, применение способа цепной подстановки требует знания взаимосвязи факторов, их соподчиненности, умения правильно их классифицировать и систематизировать.
Метод главных компонент осуществляет переход к новой системе координат y1,...,ур в исходном пространстве признаков x1,...,xp, которая является системой ортнормированных линейных комбинаций[23]:
(2.6)
где mi – математическое ожидание признака xi.
Линейные комбинации выбираются таким образом, что среди всех возможных линейных нормированных комбинаций исходных признаков первая главная компонента у1(х) обладает наибольшей дисперсией. Геометрически это выглядит как ориентация новой координатной оси у1 вдоль направления наибольшей вытянутости эллипсоида рассеивания объектов исследуемой выборки в пространстве признаков x1, ..., xp. Вторая главная компонента имеет наибольшую дисперсию среди всех оставшихся линейных преобразований, некоррелированных с первой главной компонентой. Она интерпретируется как направление наибольшей вытянутости эллипсоида рассеивания, перпендикулярное первой главной компоненте. Следующие главные компоненты определяются по аналогичной схеме. Вычисление коэффициентов главных компонент wij основано на том факте, что векторы wi = (w11, .., wpl)', ..., wp = (w1p, ..., wpp)' являются собственными (характеристическими) векторами корреляционной матрицы S. В свою очередь, соответствующие собственные числа этой матрицы равны дисперсиям проекций множества объектов на оси главных компонент.
В описанном выше методе главных компонент под критерием автоинформативности пространства признаков подразумевается, что ценную для диагностики информацию можно отразить в линейной модели, которая соответствует новой координатной оси в данном пространстве с максимальной дисперсией распределения проекций исследуемых объектов. Такой подход является продуктивным, когда явное большинство заданий «чернового» варианта теста согласованно «работает» на проявление тестируемого свойства и подавляет влияние иррелевантных факторов на распределение объектов. Также положительный результат будет получен при сравнительно небольшом объеме группы связанных информативных признаков, но при несогласованном взаимодействии посторонних факторов, под влиянием которых не нарушается однородность эллипсоида рассеивания, а лишь уменьшается вытянутость распределения объектов вдоль направления диагностируемой тенденции. В отличие от метода главных компонент факторный анализ основан не на дисперсионном критерии автоинформативности системы признаков, а ориентирован на объяснение имеющихся между признаками корреляций.
Центроидный метод. Этот метод основан на предположении о том, что каждый из исходных признаков может быть представлен как функция небольшого числа общих факторов F1, F2, …, Fk и характерного фактора Uj. При этом считается, что каждый общий фактор имеет существенное значение для анализа всех исходных признаков, т.е. фактор Fj – общий для всех X1, X2, ..., Xm. В то же время изменения в характерном факторе Uj воздействуют на значения только соответствующего признака Xj. Таким образом, характерный фактор Uj отражает ту специфику признака Xj, которая не может быть выражена через общие факторы[24].
Основные предположения факторного анализа связаны с допущением о линейности связи исходных признаков с факторами:
, (2.7)
где F1, …, Fk – общие факторы, независимые стандартизованные показатели, распределенные по нормальному закону,
U1, …, Um – характерные факторы, некоррелированные стандартизованные показатели, независящие от общих факторов,
aij – факторные нагрузки,
– числа, показывающие степень влияния характерного фактора Uj на Xj.
Задачу факторного анализа можно сформулировать следующим образом: определить минимальное число k таких факторов F1, …, Fk, после учета которых исходная корреляционная матрица «исчерпается», внедиагональные элементы ее станут близкими к нулю. Другими словами, это значит, что после учета k факторов все остаточные корреляции между исходными признаками должны стать незначимыми.
Другие приемы анализа, такие как интегральный и логарифмический, позволяют достичь более высокой точности расчетов, однако эти методы имеют более ограниченную сферу применения и требуют проведения большого объема вычислений, что неудобно для проведения оперативного анализа.
Факторный анализ часто применяется при решении задач классификации, а также при построении многомерных градировочных моделей. В качестве недостатков этого метода можно выделить следующие[25]:
– нет однозначного подхода к определению числа значимых переменных. Статистические данные могут содержать случайную ошибку, вызывающую появление дополнительных факторов. Существует множество способов отделения значимых переменных от незначимых, однако в каждом конкретном случае требуется индивидуальный подход;
– сложность интерпретации переменных – преобразование (2.2) можно провести бесконечным множеством способов, при этом выяснить физическую суть каждой новой переменной довольно сложно, а часто и невозможно.
На основании вышеизложенного можно сделать вывод о важности применения таких инструментальных средств, которые бы в полной мере отвечали целям и задачам мониторинга рынка труда. Среди данных инструментальных средств выделяется инструментарий качественного и количественного сбора данных. Основные методы качественных исследований: фокус-группы, глубинные интервью, анализ протокола. Методами количественных исследований являются различные виды опросов и контент-анализ. К достоинствам качественных методов исследования можно отнести широту охвата проблемы, тогда как преимуществами количественных методов исследования является массовость проведения исследования при некоторой ограниченности круга проблемы. Еще одним достоинством информации, полученной количественными методами исследования, является возможность ее обработки методами статистического и математического анализа, а также наглядность предоставления результатов исследований в виде графиков и таблиц. В инструментарий анализа количественных данных входят факторный и кластерный анализы, дисперсионный и конджойт-анализ. В данном разделе были рассмотрены такие часто используемые инструменты, как корреляционно-регрессионный и факторный анализы. Были выделены их достоинства, недостатки, а также область применения данных инструментов в процессе проведения мониторинга рынка труда.
[1] Севрук А.И., Филимонова И.В., Юнина Е.А. Мониторинг как технология информационного обеспечения качества образования // Стандарты и мониторинг в образовании. 2002. №3. С.35-44.
[2] Фокус-группы // Материалы сайта исследовательской компании INFOWAVE // http://www.infowave.ru/lib/methods/focus_group.
[3] Интервью // Материалы сайта научно-исследовательского центра “Экономика, Общество, Наука” // http://www.rc-ess.ru/interview.htm.
[4] Боровкова Т.И., Морев И.А. Мониторинг развития системы образования. Часть 2. Практические аспекты: Учебное пособие. – Владивосток: Изд-во Дальневосточного университета, 2004. – 134 с., 115 c.
[5] Интервью // Материалы сайта научно-исследовательского центра Экономика, Общество, Наука // http://www.rc-ess.ru/interview.htm.
[6] Глубинное интервью // Материалы сайта исследовательской компании INFOWAVE // http://www.infowave.ru/lib/methods/deep_interview/.
[7] Анализ протокола // Материалы сайта исследовательской компании INFOWAVE // http://www.infowave.ru/lib/methods/analysis/.
[8] Коновалов А.В., Романенко М.А. Множественная регрессия // Материалы сайта Статистика // http://www.yartel.ru/stat/wmnreg.html.
[9] Коновалов А.В., Романенко М.А. Множественная регрессия // Материалы сайта Статистика // http://www.yartel.ru/stat/wmnreg.html.
[10] Коновалов А.В., Романенко М.А. Множественная регрессия // Материалы сайта Статистика // http://www.yartel.ru/stat/wmnreg.html.
[11] Коновалов А.В., Романенко М.А. Многомерное шкалирование // Материалы сайта Статистика // http://www.yartel.ru/stat/wshkalir.html.
[12] То же.
[13] Коновалов А.В., Романенко М.А. Множественная регрессия // Материалы сайта Статистика // http://www.yartel.ru/stat/wmnreg.html.
[14] Дюк В. Метод главных компонент // Материалы сайта Статистика // http://www.yartel.ru/stat/mgk.html.
[15] Факторный анализ // Материалы сайта Статистика в экономике // http://www.stateco.ru/node/35.
[16] Детерминированный факторный анализ // Материалы сайта Дистанционный консалтинг // http://www.dist-cons.ru/modules/DuPont/section2.html.
[17] Детерминированный факторный анализ // Материалы сайта Дистанционный консалтинг // http://www.dist-cons.ru/modules/DuPont/section2.html.
[18] Факторный анализ // Материалы сайта Статистика в экономике // http://www.stateco.ru/node/35.
[19] Детерминированный факторный анализ // Материалы сайта Дистанционный консалтинг // http://www.dist-cons.ru/modules/DuPont/section2.html.
[20] Факторный анализ // Материалы сайта Статистика в экономике // http://www.stateco.ru/node/35.
[21] Детерминированный факторный анализ // Материалы сайта Дистанционный консалтинг // http://www.dist-cons.ru/modules/DuPont/section2.html.
[22] То же.
[23] Дюк В. Метод главных компонент // Материалы сайта Статистика // http://www.yartel.ru/stat/mgk.html.
[24] Коновалов А.В., Романенко М.А. Факторный анализ // Материалы сайта Статистика // http://www.yartel.ru/stat/wfuck.html.
[25] Факторный анализ // Материалы сайта Статистика в экономике // http://www.stateco.ru/node/35.
| Предыдущая |