

Орлов А.И.
Прикладная статистика
М.: Издательство «Экзамен», 2004.
| Предыдущая |
Часть 1. Фундамент прикладной статистики
1.2. Основы вероятностно-статистических методов описания неопределенностей в прикладной статистике
1.2.4. Случайные величины и их распределения
Распределения случайных величин и функции распределения. Распределение числовой случайной величины – это функция, которая однозначно определяет вероятность того, что случайная величина принимает заданное значение или принадлежит к некоторому заданному интервалу.
Первое – если случайная величина принимает конечное число значений. Тогда распределение задается функцией Р(Х = х), ставящей каждому возможному значению х случайной величины Х вероятность того, что Х = х.
Второе – если случайная величина принимает бесконечно много значений. Это возможно лишь тогда, когда вероятностное пространство, на котором определена случайная величина, состоит из бесконечного числа элементарных событий. Тогда распределение задается набором вероятностей P(a <X <b) для всех пар чисел a, b таких, что a<b. Распределение может быть задано с помощью т.н. функции распределения F(x) = P(X<x), определяющей для всех действительных х вероятность того, что случайная величина Х принимает значения, меньшие х. Ясно, что
P(a <X <b) = F(b) – F(a).
Это соотношение показывает, что как распределение может быть рассчитано по функции распределения, так и, наоборот, функция распределения – по распределению.
Используемые в вероятностно-статистических методах принятия решений и других прикладных исследованиях функции распределения бывают либо дискретными, либо непрерывными, либо их комбинациями.
Дискретные функции распределения соответствуют дискретным случайным величинам, принимающим конечное число значений или же значения из множества, элементы которого можно перенумеровать натуральными числами (такие множества в математике называют счетными). Их график имеет вид ступенчатой лестницы (рис. 1).
Пример 1. Число Х дефектных изделий в партии принимает значение 0 с вероятностью 0,3, значение 1 с вероятностью 0,4, значение 2 с вероятностью 0,2 и значение 3 с вероятностью 0,1. График функции распределения случайной величины Х изображен на рис.1.
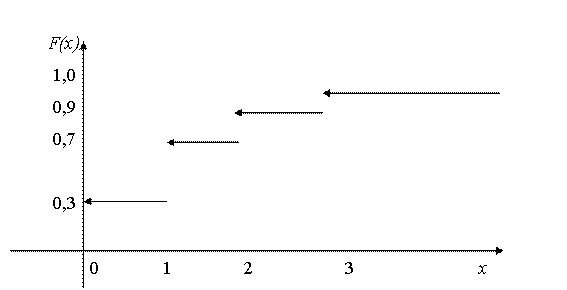
Рис.1. График функции распределения числа дефектных изделий.
Непрерывные
функции распределения не имеют скачков. Они монотонно возрастают [1] при
увеличении аргумента – от 0 при ![]() до 1 при
до 1 при ![]() . Случайные величины, имеющие непрерывные функции
распределения, называют непрерывными.
. Случайные величины, имеющие непрерывные функции
распределения, называют непрерывными.
Непрерывные функции распределения, используемые в вероятностно-статистических методах принятия решений, имеют производные. Первая производная f(x) функции распределения F(x) называется плотностью вероятности,
![]()
По плотности вероятности можно определить функцию распределения:
![]()
Для любой функции распределения
![]()
а потому
![]()
Перечисленные свойства функций распределения постоянно используются в вероятностно-статистических методах принятия решений. В частности, из последнего равенства вытекает конкретный вид констант в формулах для плотностей вероятностей, рассматриваемых ниже.
Пример 2. Часто используется следующая функция распределения:
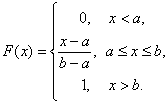 (1)
(1)
где a и b – некоторые числа, a<b. Найдем плотность вероятности этой функции распределения:
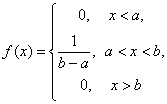
(в точках x = a и x = b производная функции F(x) не существует).
Случайная величина с функцией распределения (1) называется «равномерно распределенной на отрезке [a; b]».
Смешанные функции распределения встречаются, в частности, тогда, когда наблюдения в какой-то момент прекращаются. Например, при анализе статистических данных, полученных при использовании планов испытаний на надежность, предусматривающих прекращение испытаний по истечении некоторого срока. Или при анализе данных о технических изделиях, потребовавших гарантийного ремонта.
Пример 3. Пусть, например, срок службы электрической лампочки – случайная величина с функцией распределения F(t), а испытание проводится до выхода лампочки из строя, если это произойдет менее чем за 100 часов от начала испытаний, или до момента t0 = 100 часов. Пусть G(t) – функция распределения времени эксплуатации лампочки в исправном состоянии при этом испытании. Тогда
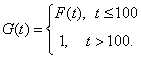
Функция G(t) имеет скачок в точке t0, поскольку соответствующая случайная величина принимает значение t0 с вероятностью 1-F(t0)>0.
Характеристики случайных величин. В вероятностно-статистических методах принятия решений используется ряд характеристик случайных величин, выражающихся через функции распределения и плотности вероятностей.
При описании дифференциации доходов, при нахождении доверительных границ для параметров распределений случайных величин и во многих иных случаях используется такое понятие, как «квантиль порядка р», где 0 < p < 1 (обозначается хр). Квантиль порядка р – значение случайной величины, для которого функция распределения принимает значение р или имеет место «скачок» со значения меньше р до значения больше р (рис.2). Может случиться, что это условие выполняется для всех значений х, принадлежащих этому интервалу (т.е. функция распределения постоянна на этом интервале и равна р). Тогда каждое такое значение называется «квантилем порядка р». Для непрерывных функций распределения, как правило, существует единственный квантиль хр порядка р (рис.2), причем
F(xp) = p. (2)
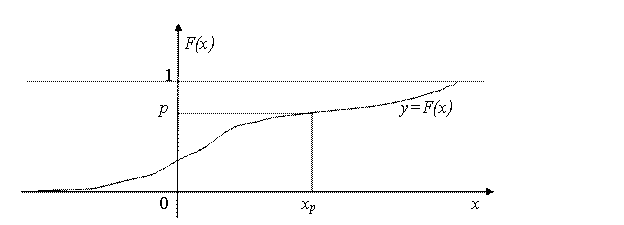
Рис.2. Определение квантиля хр порядка р.
Пример 4. Найдем квантиль хр порядка р для функции распределения F(x) из (1).
При 0 < p < 1 квантиль хр находится из уравнения
![]() ,
,
т.е. хр = a + p(b – a) = a(1- p) +bp. При p = 0 любое x < a является квантилем порядка p = 0. Квантилем порядка p = 1 является любое число x > b.
Для дискретных распределений, как правило, не существует хр, удовлетворяющих уравнению (2). Точнее, если распределение случайной величины дается табл.1, где x1 < x2 < … < xk, то равенство (2), рассматриваемое как уравнение относительно хр, имеет решения только для k значений p, а именно,
p = p1,
p = p1 + p2,
p = p1 + p2 + p3,
…
p = p1 + p2 + … + pm, 3 < m < k,
…
p = p1 + p2 + … + pk.
Таблица 1.
Распределение дискретной случайной величины
Значения x случайной величины Х |
х1 |
х2 |
… |
хk |
Вероятности P(X =x) |
p1 |
p2 |
… |
pk |
Для перечисленных k значений вероятности p решение хр уравнения (2) неединственно, а именно,
F(x) = p1 + p2 + … + pm
для всех х таких, что xm < x < xm+1. Т.е. хр – любое число из интервала (xm; xm+1]. Для всех остальных р из промежутка (0;1), не входящих в перечень (3), имеет место «скачок» со значения меньше р до значения больше р. А именно, если
p1 + p2 + … + pm <p < p1 + p2 + … + pm + pm+1,
то хр = xm+1.
Рассмотренное свойство дискретных распределений создает значительные трудности при табулировании и использовании подобных распределений, поскольку невозможным оказывается точно выдержать типовые численные значения характеристик распределения. В частности, это так для критических значений и уровней значимости непараметрических статистических критериев (см. ниже), поскольку распределения статистик этих критериев дискретны.
Большое значение в статистике имеет квантиль порядка р = ½. Он называется медианой (случайной величины Х или ее функции распределения F(x)) и обозначается Me(X). В геометрии есть понятие «медиана» - прямая, проходящая через вершину треугольника и делящая противоположную его сторону пополам. В математической статистике медиана делит пополам не сторону треугольника, а распределение случайной величины: равенство F(x0,5) = 0,5 означает, что вероятность попасть левее x0,5 и вероятность попасть правее x0,5 (или непосредственно в x0,5) равны между собой и равны ½, т.е.
P(X < x0,5) = P(X > x0,5) = ½.
Медиана указывает «центр» распределения. С точки зрения одной из современных концепций – теории устойчивых статистических процедур – медиана является более хорошей характеристикой случайной величины, чем математическое ожидание [2,7]. При обработке результатов измерений в порядковой шкале (см. главу о теории измерений) медианой можно пользоваться, а математическим ожиданием – нет.
Ясный смысл имеет такая характеристика случайной величины, как мода – значение (или значения) случайной величины, соответствующее локальному максимуму плотности вероятности для непрерывной случайной величины или локальному максимуму вероятности для дискретной случайной величины.
Если x0 – мода случайной величины с плотностью f(x), то,
как известно из дифференциального исчисления, ![]() .
.
У случайной величины может быть много мод. Так, для равномерного распределения (1) каждая точка х такая, что a < x < b, является модой. Однако это исключение. Большинство случайных величин, используемых в вероятностно-статистических методах принятия решений и других прикладных исследованиях, имеют одну моду. Случайные величины, плотности, распределения, имеющие одну моду, называются унимодальными.
Математическое ожидание для дискретных случайных величин с конечным числом значений рассмотрено в главе «События и вероятности». Для непрерывной случайной величины Х математическое ожидание М(Х) удовлетворяет равенству
![]()
являющемуся аналогом формулы (5) из утверждения 2 главы «События и вероятности».
Пример 5. Математическое ожидание для равномерно распределенной случайной величины Х равно
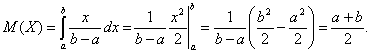
Для рассматриваемых в настоящей главе случайных величин верны все те свойства математических ожиданий и дисперсий, которые были рассмотрены ранее для дискретных случайных величин с конечным числом значений. Однако доказательства этих свойств не приводим, поскольку они требуют углубления в математические тонкости, не являющегося необходимым для понимания и квалифицированного применения вероятностно-статистических методов принятия решений.
Замечание. В настоящем учебнике сознательно обходятся математические тонкости, связанные,
в частности, с понятиями измеримых множеств и измеримых функций, ![]() -алгебры событий и т.п. Желающим освоить эти понятия необходимо
обратиться к специальной литературе, в частности, к энциклопедии [1].
-алгебры событий и т.п. Желающим освоить эти понятия необходимо
обратиться к специальной литературе, в частности, к энциклопедии [1].
Каждая из трех характеристик – математическое ожидание, медиана, мода – описывает «центр» распределения вероятностей. Понятие «центр» можно определять разными способами – отсюда три разные характеристики. Однако для важного класса распределений – симметричных унимодальных – все три характеристики совпадают.
Плотность распределения f(x) – плотность симметричного распределения, если найдется число х0 такое, что
![]() . (3)
. (3)
Равенство (3) означает, что график функции y = f(x) симметричен относительно вертикальной прямой, проходящей через центр симметрии х = х0. Из (3) следует, что функция симметричного распределения удовлетворяет соотношению
![]() (4)
(4)
Для симметричного распределения с одной модой математическое ожидание, медиана и мода совпадают и равны х0.
Наиболее важен случай симметрии относительно 0, т.е. х0 = 0. Тогда (3) и (4) переходят в равенства
![]() (5)
(5)
и
![]() (6)
(6)
соответственно. Приведенные соотношения показывают, что симметричные распределения нет необходимости табулировать при всех х, достаточно иметь таблицы при x > x0.
Отметим еще одно свойство симметричных распределений, постоянно используемое в вероятностно-статистических методах принятия решений и других прикладных исследованиях. Для непрерывной функции распределения
P(|X|<a) = P(-a <X <a) = F(a) – F(-a),
где F – функция распределения случайной величины Х. Если функция распределения F симметрична относительно 0, т.е. для нее справедлива формула (6), то
P(|X|<a)
=
Часто используют другую формулировку рассматриваемого утверждения: если
![]() ,
,
то
![]() .
.
Если ![]() и
и ![]() - квантили порядка
- квантили порядка ![]() и
и ![]() соответственно (см.
(2)) функции распределения, симметричной относительно 0, то из (6) следует, что
соответственно (см.
(2)) функции распределения, симметричной относительно 0, то из (6) следует, что
![]() .
.
От
характеристик положения – математического ожидания, медианы, моды – перейдем к
характеристикам разброса случайной величины Х: дисперсии ![]() , среднему квадратическому отклонению
, среднему квадратическому отклонению ![]() и коэффициенту
вариации v. Определение и свойства дисперсии для дискретных случайных
величин рассмотрены в предыдущей главе. Для непрерывных случайных величин
и коэффициенту
вариации v. Определение и свойства дисперсии для дискретных случайных
величин рассмотрены в предыдущей главе. Для непрерывных случайных величин
![]() .
.
Среднее квадратическое отклонение – это неотрицательное значение квадратного корня из дисперсии:
![]() .
.
Коэффициент вариации – это отношение среднего квадратического отклонения к математическому ожиданию:
![]() .
.
Коэффициент вариации применяется при M(X)>0. Он измеряет разброс в относительных единицах, в то время как среднее квадратическое отклонение – в абсолютных.
Пример 6. Для равномерно распределенной случайной величины Х найдем дисперсию, среднеквадратическое отклонение и коэффициент вариации. Дисперсия равна:
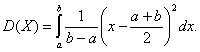
Замена переменной ![]() дает возможность
записать:
дает возможность
записать:
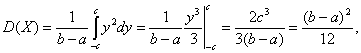
где c = (b – a)/2. Следовательно, среднее квадратическое отклонение
равно ![]() а коэффициент вариации
таков:
а коэффициент вариации
таков: ![]()
По каждой случайной величине Х определяют еще три величины – центрированную Y, нормированную V и приведенную U. Центрированная случайная величина Y – это разность между данной случайной величиной Х и ее математическим ожиданием М(Х), т.е. Y = Х – М(Х). Математическое ожидание центрированной случайной величины Y равно 0, а дисперсия – дисперсии данной случайной величины: М(Y) = 0, D(Y) = D(X). Функция распределения FY(x) центрированной случайной величины Y связана с функцией распределения F(x) исходной случайной величины X соотношением:
FY(x) =F(x + M(X)).
Для плотностей этих случайных величин справедливо равенство
fY(x) = f(x + M(X)).
Нормированная
случайная величина V – это отношение данной случайной величины Х к ее
среднему квадратическому отклонению ![]() , т.е.
, т.е. ![]() . Математическое ожидание и дисперсия нормированной случайной
величины V выражаются через характеристики Х так:
. Математическое ожидание и дисперсия нормированной случайной
величины V выражаются через характеристики Х так:
![]() ,
,
где v – коэффициент вариации исходной случайной величины Х. Для функции распределения FV(x) и плотности fV(x) нормированной случайной величины V имеем:
![]() ,
,
где F(x) – функция распределения исходной случайной величины Х, а f(x) – ее плотность вероятности.
Приведенная случайная величина U – это центрированная и нормированная случайная величина:
![]() .
.
Для приведенной случайной величины
![]() . (7)
. (7)
Нормированные, центрированные и
приведенные случайные величины постоянно используются как в теоретических
исследованиях, так и в алгоритмах, программных продуктах,
нормативно-технической и инструктивно-методической документации. В частности,
потому, что равенства ![]() позволяют упростить
обоснования методов, формулировки теорем и расчетные формулы.
позволяют упростить
обоснования методов, формулировки теорем и расчетные формулы.
Используются преобразования случайных величин и более общего плана. Так, если Y = aX + b, где a и b – некоторые числа, то
![]() (8)
(8)
Пример
7. Если ![]() то Y – приведенная случайная величина, и
формулы (8) переходят в формулы (7).
то Y – приведенная случайная величина, и
формулы (8) переходят в формулы (7).
С каждой случайной величиной Х можно связать множество случайных величин Y, заданных формулой Y = aX + b при различных a>0 и b. Это множество называют масштабно-сдвиговым семейством, порожденным случайной величиной Х. Функции распределения FY(x) составляют масштабно сдвиговое семейство распределений, порожденное функцией распределения F(x). Вместо Y = aX + b часто используют запись
![]() (9)
(9)
где
![]()
Число с называют параметром сдвига, а число d - параметром масштаба. Формула (9) показывает, что Х – результат измерения некоторой величины – переходит в У – результат измерения той же величины, если начало измерения перенести в точку с, а затем использовать новую единицу измерения, в d раз большую старой.
Для масштабно-сдвигового семейства (9) распределение Х называют стандартным. В вероятностно-статистических методах принятия решений и других прикладных исследованиях используют стандартное нормальное распределение, стандартное распределение Вейбулла-Гнеденко, стандартное гамма-распределение и др. (см. ниже).
Применяют и другие преобразования случайных величин. Например, для положительной случайной величины Х рассматривают Y = lg X, где lg X – десятичный логарифм числа Х. Цепочка равенств
FY(x) = P(lg X < x) = P(X < 10x) = F(10x)
связывает функции распределения Х и Y.
При обработке данных используют такие характеристики случайной величины Х как моменты порядка q, т.е. математические ожидания случайной величины Xq, q = 1, 2, … Так, само математическое ожидание – это момент порядка 1. Для дискретной случайной величины момент порядка q может быть рассчитан как
![]()
Для непрерывной случайной величины
![]()
Моменты порядка q называют также начальными моментами порядка q, в отличие от родственных характеристик – центральных моментов порядка q, задаваемых формулой
![]()
Так, дисперсия – это центральный момент порядка 2.
Нормальное распределение и центральная предельная теорема. В вероятностно-статистических методах принятия решений часто идет речь о нормальном распределении. Иногда его пытаются использовать для моделирования распределения исходных данных (эти попытки не всегда являются обоснованными – см. ниже). Более существенно, что многие методы обработки данных основаны на том, что расчетные величины имеют распределения, близкие к нормальному.
Пусть X1, X2,…, Xn, …– независимые одинаково
распределенные случайные величины с математическими ожиданиями M(Xi) = m и дисперсиями D(Xi) = ![]() , i = 1, 2,…, n,… Как следует из результатов предыдущей
главы,
, i = 1, 2,…, n,… Как следует из результатов предыдущей
главы,
![]()
Рассмотрим приведенную случайную
величину Un для суммы ![]() , а именно,
, а именно,
![]()
Как следует из формул (7), M(Un) = 0, D(Un) = 1.
Центральная
предельная теорема (для одинаково распределенных слагаемых). Пусть X1, X2,…, Xn, …– независимые одинаково
распределенные случайные величины с математическими ожиданиями M(Xi) = m и дисперсиями D(Xi) = ![]() , i = 1, 2,…, n,… Тогда для любого х существует
предел
, i = 1, 2,…, n,… Тогда для любого х существует
предел
![]()
где Ф(х) – функция стандартного нормального распределения.
Подробнее о функции Ф(х) – ниже (читается «фи от икс», поскольку Ф – греческая прописная буква «фи»).
Центральная
предельная теорема (ЦПТ) носит свое название по той причине, что она является
центральным, наиболее часто применяющимся математическим результатом теории
вероятностей и математической статистики. История ЦПТ занимает около 200 лет –
с
Развитие рассматриваемой тематики на этом отнюдь не прекратилось – изучали случайные величины, не имеющие дисперсии, т.е. те, для которых
![]()
(академик Б.В.Гнеденко и др.), ситуацию, когда суммируются случайные величины (точнее, случайные элементы) более сложной природы, чем числа (академики Ю.В.Прохоров, А.А.Боровков и их соратники), и т.д.
Функция распределения Ф(х) задается равенством
![]() ,
,
где ![]() - плотность
стандартного нормального распределения, имеющая довольно сложное выражение:
- плотность
стандартного нормального распределения, имеющая довольно сложное выражение:
![]() .
.
Здесь ![]() =3,1415925… - известное в геометрии число, равное отношению
длины окружности к диаметру, e = 2,718281828… - основание натуральных логарифмов (для
запоминания этого числа обратите внимание, что 1828 – год рождения писателя
Л.Н.Толстого). Как известно из математического анализа,
=3,1415925… - известное в геометрии число, равное отношению
длины окружности к диаметру, e = 2,718281828… - основание натуральных логарифмов (для
запоминания этого числа обратите внимание, что 1828 – год рождения писателя
Л.Н.Толстого). Как известно из математического анализа,
![]()
При обработке результатов наблюдений функцию нормального распределения не вычисляют по приведенным формулам, а находят с помощью специальных таблиц или компьютерных программ. Лучшие на русском языке «Таблицы математической статистики» составлены членами-корреспондентами АН СССР Л.Н. Большевым и Н.В.Смирновым [8].
Вид
плотности стандартного нормального распределения ![]() вытекает из
математической теории, которую не имеем возможности здесь рассматривать, равно
как и доказательство ЦПТ.
вытекает из
математической теории, которую не имеем возможности здесь рассматривать, равно
как и доказательство ЦПТ.
Для иллюстрации приводим небольшие таблицы функции распределения Ф(х) (табл.2) и ее квантилей (табл.3). Функция Ф(х) симметрична относительно 0, что отражается в табл.2-3.
Таблица 2.
Функция стандартного нормального распределения.
х |
Ф(х) |
х |
Ф(х) |
х |
Ф(х) |
-5,0 |
0,00000029 |
-1,0 |
0,158655 |
2,0 |
0,9772499 |
-4,0 |
0,00003167 |
-0,5 |
0,308538 |
2,5 |
0,99379033 |
-3,0 |
0,00134990 |
0,0 |
0,500000 |
3,0 |
0,99865010 |
-2,5 |
0,00620967 |
0,5 |
0,691462 |
4,0 |
0,99996833 |
-2,0 |
0,0227501 |
1,0 |
0,841345 |
5,0 |
0,99999971 |
-1,5 |
0,0668072 |
1,5 |
0,9331928 |
Если
случайная величина Х имеет функцию распределения Ф(х), то М(Х) = 0, D(X) = 1. Это утверждение доказывается в теории
вероятностей, исходя из вида плотности вероятностей ![]() . Оно согласуется с аналогичным утверждением для
характеристик приведенной случайной величины Un, что вполне естественно, поскольку ЦПТ
утверждает, что при безграничном возрастании числа слагаемых функция
распределения Un стремится к функции стандартного нормального
распределения Ф(х), причем при любом х.
. Оно согласуется с аналогичным утверждением для
характеристик приведенной случайной величины Un, что вполне естественно, поскольку ЦПТ
утверждает, что при безграничном возрастании числа слагаемых функция
распределения Un стремится к функции стандартного нормального
распределения Ф(х), причем при любом х.
Таблица 3.
Квантили стандартного нормального распределения.
р |
Квантиль порядка р |
р |
Квантиль порядка р |
0,01 |
-2,326348 |
0,60 |
0,253347 |
0,025 |
-1,959964 |
0,70 |
0,524401 |
0,05 |
-1,644854 |
0,80 |
0,841621 |
0,10 |
-1,281552 |
0,90 |
1,281552 |
0,30 |
-0,524401 |
0,95 |
1,644854 |
0,40 |
-0,253347 |
0,975 |
1,959964 |
0,50 |
0,000000 |
0,99 |
2,326348 |
Введем понятие семейства нормальных распределений. По определению нормальным распределением называется распределение случайной величины Х, для которой распределение приведенной случайной величины есть Ф(х). Как следует из общих свойств масштабно-сдвиговых семейств распределений (см. выше), нормальное распределение – это распределение случайной величины
![]() ,
,
где Х – случайная величина с
распределением Ф(Х), причем m = M(Y), ![]() = D(Y). Нормальное распределение с параметрами сдвига m и масштаба
= D(Y). Нормальное распределение с параметрами сдвига m и масштаба ![]() обычно обозначается N(m,
обычно обозначается N(m, ![]() ) (иногда используется обозначение N(m,
) (иногда используется обозначение N(m, ![]() )).
)).
Как
следует из (8), плотность вероятности нормального распределения N(m, ![]() ) есть
) есть
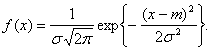
Нормальные
распределения образуют масштабно-сдвиговое семейство. При этом параметром
масштаба является d = 1/![]() , а параметром сдвига c = - m/
, а параметром сдвига c = - m/![]() .
.
Для центральных моментов третьего и четвертого порядка нормального распределения справедливы равенства
![]()
Эти равенства лежат в основе классических методов проверки того, что результаты наблюдений подчиняются нормальному распределению. В настоящее время нормальность обычно рекомендуется проверять по критерию W Шапиро – Уилка. Проблема проверки нормальности обсуждается ниже.
Если
случайные величины Х1 и Х2 имеют функции
распределения N(m1, ![]() 1) и N(m2,
1) и N(m2, ![]() 2) соответственно, то Х1 + Х2 имеет распределение
2) соответственно, то Х1 + Х2 имеет распределение ![]() Следовательно, если
случайные величины X1, X2,…, Xn независимы и имеют одно и тоже
распределение N(m,
Следовательно, если
случайные величины X1, X2,…, Xn независимы и имеют одно и тоже
распределение N(m, ![]() ), то их среднее арифметическое
), то их среднее арифметическое
![]()
имеет распределение N(m, ![]() ). Эти свойства нормального распределения постоянно
используются в различных вероятностно-статистических методах принятия решений,
в частности, при статистическом регулировании технологических процессов и в
статистическом приемочном контроле по количественному признаку.
). Эти свойства нормального распределения постоянно
используются в различных вероятностно-статистических методах принятия решений,
в частности, при статистическом регулировании технологических процессов и в
статистическом приемочном контроле по количественному признаку.
С помощью нормального распределения определяются три распределения, которые в настоящее время часто используются при статистической обработке данных.
Распределение ![]() (хи - квадрат) –
распределение случайной величины
(хи - квадрат) –
распределение случайной величины
![]()
где случайные величины X1, X2,…, Xn независимы и имеют одно и тоже распределение N(0,1). При этом число слагаемых, т.е. n, называется «числом степеней свободы» распределения хи – квадрат.
Распределение t Стьюдента – это распределение случайной величины
![]()
где случайные величины U и X независимы, U имеет распределение стандартное
нормальное распределение N(0,1), а X – распределение хи – квадрат с n степенями свободы. При этом n называется «числом степеней свободы»
распределения Стьюдента. Это распределение было введено в
Распределение Фишера – это распределение случайной величины
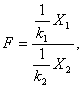
где случайные величины Х1 и Х2 независимы и имеют распределения хи – квадрат с числом степеней свободы k1 и k2 соответственно. При этом пара (k1, k2) – пара «чисел степеней свободы» распределения Фишера, а именно, k1 – число степеней свободы числителя, а k2 – число степеней свободы знаменателя. Распределение случайной величины F названо в честь великого английского статистика Р.Фишера (1890-1962), активно использовавшего его в своих работах.
Выражения для функций распределения хи - квадрат, Стьюдента и Фишера, их плотностей и характеристик, а также таблицы можно найти в специальной литературе (см., например, [8]).
Как уже отмечалось, нормальные распределения в настоящее время часто используют в вероятностных моделях в различных прикладных областях. В чем причина такой широкой распространенности этого двухпараметрического семейства распределений? Она проясняется следующей теоремой.
Центральная предельная теорема (для разнораспределенных слагаемых). Пусть X1, X2,…, Xn,… - независимые случайные величины с математическими ожиданиями М(X1), М(X2),…, М(Xn), … и дисперсиями D(X1), D(X2),…, D(Xn), … соответственно. Пусть
![]()
Тогда при справедливости некоторых условий, обеспечивающих малость вклада любого из слагаемых в Un,
![]()
для любого х.
Условия, о которых идет речь, не будем здесь формулировать. Их можно найти в специальной литературе (см., например, [6]). «Выяснение условий, при которых действует ЦПТ, составляет заслугу выдающихся русских ученых А.А.Маркова (1857-1922) и, в особенности, А.М.Ляпунова (1857-1918)» [9, с.197].
Центральная предельная теорема показывает, что в случае, когда результат измерения (наблюдения) складывается под действием многих причин, причем каждая из них вносит лишь малый вклад, а совокупный итог определяется аддитивно, т.е. путем сложения, то распределение результата измерения (наблюдения) близко к нормальному.
Иногда считают, что для нормальности распределения достаточно того, что результат измерения (наблюдения) Х формируется под действием многих причин, каждая из которых оказывает малое воздействие. Это не так. Важно, как эти причины действуют. Если аддитивно – то Х имеет приближенно нормальное распределение. Если мультипликативно (т.е. действия отдельных причин перемножаются, а не складываются), то распределение Х близко не к нормальному, а к т.н. логарифмически нормальному, т.е. не Х, а lg X имеет приблизительно нормальное распределение. Если же нет оснований считать, что действует один из этих двух механизмов формирования итогового результата (или какой-либо иной вполне определенный механизм), то про распределение Х ничего определенного сказать нельзя.
Из сказанного вытекает, что в конкретной прикладной задаче нормальность результатов измерений (наблюдений), как правило, нельзя установить из общих соображений, ее следует проверять с помощью статистических критериев. Или же использовать непараметрические статистические методы, не опирающиеся на предположения о принадлежности функций распределения результатов измерений (наблюдений) к тому или иному параметрическому семейству.
Непрерывные распределения, используемые в вероятностно-статистических методах принятия решений. Кроме масштабно-сдвигового семейства нормальных распределений, широко используют ряд других семейств распределения – логарифмически нормальных, экспоненциальных, Вейбулла-Гнеденко, гамма-распределений. Рассмотрим эти семейства.
Случайная
величина Х имеет логарифмически нормальное распределение, если случайная
величина Y = lg X имеет нормальное распределение. Тогда Z = ln X = 2,3026…Y также имеет нормальное распределение ![]() N(a1,σ1), где ln X - натуральный логарифм Х.
Плотность логарифмически нормального распределения такова:
N(a1,σ1), где ln X - натуральный логарифм Х.
Плотность логарифмически нормального распределения такова:
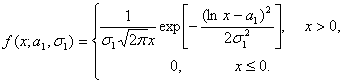
Из центральной предельной теоремы следует, что произведение X = X1X2…Xn независимых положительных случайных величин Xi, i = 1, 2,…, n, при больших n можно аппроксимировать логарифмически нормальным распределением. В частности, мультипликативная модель формирования заработной платы или дохода приводит к рекомендации приближать распределения заработной платы и дохода логарифмически нормальными законами. Для России эта рекомендация оказалась обоснованной - статистические данные подтверждают ее.
Имеются и другие вероятностные модели, приводящие к логарифмически нормальному закону. Классический пример такой модели дан А.Н.Колмогоровым [10], который из физически обоснованной системы постулатов вывел заключение о том, что размеры частиц при дроблении кусков руды, угля и т.п. на шаровых мельницах имеют логарифмически нормальное распределение.
Перейдем к другому
семейству распределений, широко используемому в различных
вероятностно-статистических методах принятия решений и других прикладных
исследованиях, - семейству экспоненциальных распределений. Начнем с
вероятностной модели, приводящей к таким распределениям. Для этого рассмотрим
"поток событий", т.е. последовательность событий, происходящих одно
за другим в какие-то моменты времени. Примерами могут служить: поток вызовов на
телефонной станции; поток отказов оборудования в технологической цепочке; поток
отказов изделий при испытаниях продукции; поток обращений клиентов в отделение
банка; поток покупателей, обращающихся за товарами и услугами, и т.д. В теории
потоков событий справедлива теорема, аналогичная центральной предельной
теореме, но в ней речь идет не о суммировании случайных величин, а о
суммировании потоков событий. Рассматривается суммарный поток, составленный из
большого числа независимых потоков, ни один из которых не оказывает
преобладающего влияния на суммарный поток. Например, поток вызовов, поступающих
на телефонную станцию, слагается из большого числа независимых потоков вызовов,
исходящих от отдельных абонентов. Доказано [6], что в случае, когда
характеристики потоков не зависят от времени, суммарный поток полностью
описывается одним числом ![]() - интенсивностью
потока. Для суммарного потока рассмотрим случайную величину Х - длину
промежутка времени между последовательными событиями. Ее функция распределения
имеет вид
- интенсивностью
потока. Для суммарного потока рассмотрим случайную величину Х - длину
промежутка времени между последовательными событиями. Ее функция распределения
имеет вид
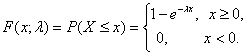 (10)
(10)
Это распределение называется экспоненциальным распределением, т.к. в формуле (10) участвует экспоненциальная функция e-λx. Величина 1/λ - масштабный параметр. Иногда вводят и параметр сдвига с, экспоненциальным называют распределение случайной величины Х + с, где распределение Х задается формулой (10).
Экспоненциальные распределения - частный случай т. н. распределений Вейбулла - Гнеденко. Они названы по фамилиям инженера В. Вейбулла, введшего эти распределения в практику анализа результатов усталостных испытаний, и математика Б.В.Гнеденко (1912-1995), получившего такие распределения в качестве предельных при изучении максимального из результатов испытаний. Пусть Х - случайная величина, характеризующая длительность функционирования изделия, сложной системы, элемента (т.е. ресурс, наработку до предельного состояния и т.п.), длительность функционирования предприятия или жизни живого существа и т.д. Важную роль играет интенсивность отказа
![]() (11)
(11)
где F(x) и f(x) - функция распределения и плотность случайной величины Х.
Опишем типичное поведение интенсивности отказа. Весь интервал времени можно разбить на три периода. На первом из них функция λ(х) имеет высокие значения и явную тенденцию к убыванию (чаще всего она монотонно убывает). Это можно объяснить наличием в рассматриваемой партии единиц продукции с явными и скрытыми дефектами, которые приводят к относительно быстрому выходу из строя этих единиц продукции. Первый период называют "периодом приработки" (или "обкатки"). Именно на него обычно распространяется гарантийный срок.
Затем наступает период нормальной эксплуатации, характеризующийся приблизительно постоянной и сравнительно низкой интенсивностью отказов. Природа отказов в этот период носит внезапный характер (аварии, ошибки эксплуатационных работников и т.п.) и не зависит от длительности эксплуатации единицы продукции.
Наконец, последний период эксплуатации - период старения и износа. Природа отказов в этот период - в необратимых физико-механических и химических изменениях материалов, приводящих к прогрессирующему ухудшению качества единицы продукции и окончательному выходу ее из строя.
Каждому периоду соответствует свой вид функции λ(х). Рассмотрим класс степенных зависимостей
λ(х) = λ0bxb-1, (12)
где λ0 > 0 и b > 0 - некоторые числовые параметры. Значения b < 1, b = 0 и b > 1 отвечают виду интенсивности отказов в периоды приработки, нормальной эксплуатации и старения соответственно.
Соотношение (11) при заданной интенсивности отказа λ(х) - дифференциальное уравнение относительно функции F(x). Из теории дифференциальных уравнений следует, что
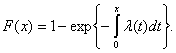 (13)
(13)
Подставив (12) в (13), получим, что
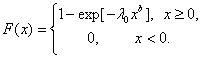 (14)
(14)
Распределение, задаваемое формулой (14) называется распределением Вейбулла - Гнеденко. Поскольку
![]()
где
![]() (15)
(15)
то из формулы (14) следует, что величина а, задаваемая формулой (15), является масштабным параметром. Иногда вводят и параметр сдвига, т.е. функциями распределения Вейбулла - Гнеденко называют F(x - c), где F(x) задается формулой (14) при некоторых λ0 и b.
Плотность распределения Вейбулла - Гнеденко имеет вид
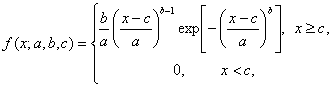 (16)
(16)
где a > 0 - параметр масштаба, b > 0 - параметр формы, с - параметр сдвига. При этом параметр а из формулы (16) связан с параметром λ0 из формулы (14) соотношением, указанным в формуле (15).
Экспоненциальное распределение - весьма частный случай распределения Вейбулла - Гнеденко, соответствующий значению параметра формы b = 1.
Распределение Вейбулла - Гнеденко применяется также при построении вероятностных моделей ситуаций, в которых поведение объекта определяется "наиболее слабым звеном". Подразумевается аналогия с цепью, сохранность которой определяется тем ее звеном, которое имеет наименьшую прочность. Другими словами, пусть X1, X2,…, Xn - независимые одинаково распределенные случайные величины,
X(1) = min (X1, X2,…, Xn), X(n) = max (X1, X2,…, Xn).
В ряде прикладных задач большую роль играют X(1) и X(n), в частности, при исследовании максимально возможных значений ("рекордов") тех или иных значений, например, страховых выплат или потерь из-за коммерческих рисков, при изучении пределов упругости и выносливости стали, ряда характеристик надежности и т.п. Показано, что при больших n распределения X(1) и X(n), как правило, хорошо описываются распределениями Вейбулла - Гнеденко. Основополагающий вклад в изучение распределений X(1) и X(n) внес советский математик Б.В.Гнеденко. Использованию полученных результатов в экономике, менеджменте, технике и других областях посвящены труды В. Вейбулла, Э. Гумбеля, В.Б. Невзорова, Э.М. Кудлаева и многих иных специалистов.
Перейдем к семейству гамма-распределений. Они широко применяются в экономике и менеджменте, теории и практике надежности и испытаний, в различных областях техники, метеорологии и т.д. В частности, гамма-распределению подчинены во многих ситуациях такие величины, как общий срок службы изделия, длина цепочки токопроводящих пылинок, время достижения изделием предельного состояния при коррозии, время наработки до k-го отказа, k = 1, 2, …, и т.д. Продолжительность жизни больных хроническими заболеваниями, время достижения определенного эффекта при лечении в ряде случаев имеют гамма-распределение. Это распределение наиболее адекватно для описания спроса в экономико-математических моделях управления запасами (логистики).
Плотность гамма-распределения имеет вид
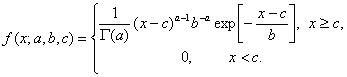 (17)
(17)
Плотность вероятности в формуле (17) определяется тремя параметрами a, b, c, где a>0, b>0. При этом a является параметром формы, b - параметром масштаба и с - параметром сдвига. Множитель 1/Γ(а) является нормировочным, он введен, чтобы
![]()
Здесь Γ(а) - одна из используемых в математике специальных функций, так называемая "гамма-функция", по которой названо и распределение, задаваемое формулой (17),
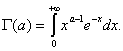
При фиксированном а формула (17) задает масштабно-сдвиговое семейство распределений, порождаемое распределением с плотностью
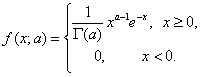 (18)
(18)
Распределение вида (18) называется стандартным гамма-распределением. Оно получается из формулы (17) при b = 1 и с = 0.
Частным случаем гамма-распределений при а = 1 являются экспоненциальные распределения (с λ = 1/b). При натуральном а и с=0 гамма-распределения называются распределениями Эрланга. С работ датского ученого К.А.Эрланга (1878-1929), сотрудника Копенгагенской телефонной компании, изучавшего в 1908-1922 гг. функционирование телефонных сетей, началось развитие теории массового обслуживания. Эта теория занимается вероятностно-статистическим моделированием систем, в которых происходит обслуживание потока заявок, с целью принятия оптимальных решений. Распределения Эрланга используют в тех же прикладных областях, в которых применяют экспоненциальные распределения. Это основано на следующем математическом факте: сумма k независимых случайных величин, экспоненциально распределенных с одинаковыми параметрами λ и с, имеет гамма-распределение с параметром формы а = k, параметром масштаба b = 1/λ и параметром сдвига kc. При с = 0 получаем распределение Эрланга.
Если случайная величина X имеет гамма-распределение с параметром формы а таким, что d = 2a - целое число, b = 1 и с = 0, то 2Х имеет распределение хи-квадрат с d степенями свободы.
Случайная величина X с гвмма-распределением имеет следующие характеристики:
- математическое ожидание М(Х) = ab + c,
- дисперсию D(X) = σ2 = ab2,
-
коэффициент вариации ![]()
-
асимметрию ![]()
-
эксцесс ![]()
Нормальное распределение - предельный случай гамма-распределения. Точнее, пусть Z - случайная величина, имеющая стандартное гамма-распределение, заданное формулой (18). Тогда
![]()
для любого действительного числа х, где Ф(х) - функция стандартного нормального распределения N(0,1).
В прикладных исследованиях используются и другие параметрические семейства распределений, из которых наиболее известны система кривых Пирсона, ряды Эджворта и Шарлье. Здесь они не рассматриваются.
Дискретные распределения, используемые в вероятностно-статистических методах принятия решений. Наиболее часто используют три семейства дискретных распределений - биномиальных, гипергеометрических и Пуассона, а также некоторые другие семейства - геометрических, отрицательных биномиальных, мультиномиальных, отрицательных гипергеометрических и т.д.
Как уже говорилось, биномиальное распределение имеет место при независимых испытаниях, в каждом из которых с вероятностью р появляется событие А. Если общее число испытаний n задано, то число испытаний Y, в которых появилось событие А, имеет биномиальное распределение. Для биномиального распределения вероятность принятия случайной величиной Y значения y определяется формулой
![]() (19)
(19)
где
![]()
- число сочетаний из n элементов по y, известное из комбинаторики. Для всех y, кроме 0, 1, 2, …, n, имеем P(Y=y)=0. Биномиальное распределение при фиксированном объеме выборки n задается параметром p, т.е. биномиальные распределения образуют однопараметрическое семейство. Они применяются при анализе данных выборочных исследований [2], в частности, при изучении предпочтений потребителей, выборочном контроле качества продукции по планам одноступенчатого контроля, при испытаниях совокупностей индивидуумов в демографии, социологии, медицине, биологии и др.
Если Y1 и Y2 - независимые биномиальные случайные величины с одним и тем же параметром p0, определенные по выборкам с объемами n1 и n2 соответственно, то Y1 + Y2 - биномиальная случайная величина, имеющая распределение (19) с р = p0 и n = n1 + n2. Это замечание расширяет область применимости биномиального распределения, позволяя объединять результаты нескольких групп испытаний, когда есть основания полагать, что всем этим группам соответствует один и тот же параметр.
Характеристики биномиального распределения вычислены ранее:
M(Y) = np, D(Y) = np(1-p).
В разделе "События и вероятности" для биномиальной случайной величины доказан закон больших чисел:
![]()
для любого ![]() . С помощью центральной предельной теоремы закон больших
чисел можно уточнить, указав, насколько Y/n отличается от р.
. С помощью центральной предельной теоремы закон больших
чисел можно уточнить, указав, насколько Y/n отличается от р.
Теорема Муавра-Лапласа. Для любых чисел a и b, a<b, имеем
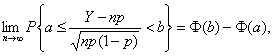
где Ф(х) – функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1.
Для доказательства достаточно воспользоваться представлением Y в виде суммы независимых случайных величин, соответствующих исходам отдельных испытаний, формулами для M(Y) и D(Y) и центральной предельной теоремой.
Эта
теорема для случая р = ½ доказана английским математиком
А.Муавром (1667-1754) в
Гипергеометрическое распределение имеет место при выборочном контроле конечной совокупности объектов объема N по альтернативному признаку. Каждый контролируемый объект классифицируется либо как обладающий признаком А, либо как не обладающий этим признаком. Гипергеометрическое распределение имеет случайная величина Y, равная числу объектов, обладающих признаком А в случайной выборке объема n, где n<N. Например, число Y дефектных единиц продукции в случайной выборке объема n из партии объема N имеет гипергеометрическое распределение, если n<N. Другой пример – лотерея. Пусть признак А билета – это признак «быть выигрышным». Пусть всего билетов N, а некоторое лицо приобрело n из них. Тогда число выигрышных билетов у этого лица имеет гипергеометрическое распределение.
Для гипергеометрического распределения вероятность принятия случайной величиной Y значения y имеет вид
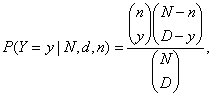 (20)
(20)
где D – число объектов, обладающих признаком А, в рассматриваемой совокупности объема N. При этом y принимает значения от max{0, n - (N - D)} до min{n, D}, при прочих y вероятность в формуле (20) равна 0. Таким образом, гипергеометрическое распределение определяется тремя параметрами – объемом генеральной совокупности N, числом объектов D в ней, обладающих рассматриваемым признаком А, и объемом выборки n.
Простой
случайной выборкой объема n из совокупности объема N называется выборка, полученная в
результате случайного отбора, при котором любой из ![]() наборов из n объектов имеет одну и ту же
вероятность быть отобранным. Методы случайного отбора выборок респондентов
(опрашиваемых) или единиц штучной продукции рассматриваются в
инструктивно-методических и нормативно-технических документах. Один из методов
отбора таков: объекты отбирают один из другим, причем на каждом шаге каждый из
оставшихся в совокупности объектов имеет одинаковые шансы быть отобранным. В
литературе для рассматриваемого типа выборок используются также термины
«случайная выборка», «случайная выборка без возвращения».
наборов из n объектов имеет одну и ту же
вероятность быть отобранным. Методы случайного отбора выборок респондентов
(опрашиваемых) или единиц штучной продукции рассматриваются в
инструктивно-методических и нормативно-технических документах. Один из методов
отбора таков: объекты отбирают один из другим, причем на каждом шаге каждый из
оставшихся в совокупности объектов имеет одинаковые шансы быть отобранным. В
литературе для рассматриваемого типа выборок используются также термины
«случайная выборка», «случайная выборка без возвращения».
Поскольку объемы генеральной совокупности (партии) N и выборки n обычно известны, то подлежащим оцениванию параметром гипергеометрического распределения является D. В статистических методах управления качеством продукции D – обычно число дефектных единиц продукции в партии. Представляет интерес также характеристика распределения D/N – уровень дефектности.
Для гипергеометрического распределения
![]()
Последний множитель в выражении для дисперсии близок к 1, если N>10n. Если при этом сделать замену p = D/N, то выражения для математического ожидания и дисперсии гипергеометрического распределения перейдут в выражения для математического ожидания и дисперсии биномиального распределения. Это не случайно. Можно показать, что
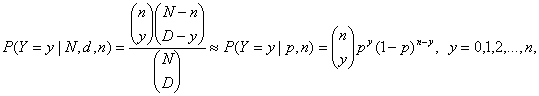
при N>10n, где p = D/N. Справедливо предельное соотношение
![]()
и этим предельным соотношением можно пользоваться при N>10n.
Третье широко используемое дискретное распределение – распределение Пуассона. Случайная величина Y имеет распределение Пуассона, если
![]() ,
,
где λ – параметр распределения Пуассона, и P(Y=y)=0 для всех прочих y (при y=0 обозначено 0! =1). Для распределения Пуассона
M(Y) = λ, D(Y) = λ.
Это распределение названо в честь
французского математика С.Д.Пуассона (1781-1840), впервые получившего его в
![]()
Поэтому распределение Пуассона (в старой терминологии «закон распределения») часто называют также «законом редких событий».
Распределение Пуассона возникает в теории потоков событий (см. выше). Доказано, что для простейшего потока с постоянной интенсивностью Λ число событий (вызовов), происшедших за время t, имеет распределение Пуассона с параметром λ = Λt. Следовательно, вероятность того, что за время t не произойдет ни одного события, равна e-Λt, т.е. функция распределения длины промежутка между событиями является экспоненциальной.
Распределение Пуассона используется при анализе результатов выборочных маркетинговых обследований потребителей, расчете оперативных характеристик планов статистического приемочного контроля в случае малых значений приемочного уровня дефектности, для описания числа разладок статистически управляемого технологического процесса в единицу времени, числа «требований на обслуживание», поступающих в единицу времени в систему массового обслуживания, статистических закономерностей несчастных случаев и редких заболеваний, и т.д.
Описание иных параметрических семейств дискретных распределений и возможности их практического использования рассматриваются в литературе.
[1] В некоторых случаях, например, при изучении цен, объемов выпуска или суммарной наработки на отказ в задачах надежности, функции распределения постоянны на некоторых интервалах, в которые значения исследуемых случайных величин не могут попасть.
| Предыдущая |