

Орлов А.И.
Нечисловая статистика
М.: МЗ-Пресс, 2004.
| Предыдущая |
Глава 4. Статистика интервальных данных
4.2. Интервальные данные в задачах оценивания
Поясним теоретические концепции статистики интервальных данных на простых примерах.
Пример 1. Оценивание математического ожидания. Пусть необходимо оценить математическое ожидание случайной величины с помощью обычной оценки - среднего арифметического результатов наблюдений, т.е.
![]()
Тогда при справедливости ограничений
(1) на абсолютные погрешности имеем ![]() Таким образом, нотна полностью известна и не
зависит от многомерной точки, в которой берется. Вполне естественно: если
каждый результат наблюдения известен с точностью до
Таким образом, нотна полностью известна и не
зависит от многомерной точки, в которой берется. Вполне естественно: если
каждый результат наблюдения известен с точностью до ![]() , то и
среднее арифметическое известно с той же точностью. Ведь возможна
систематическая ошибка - если к каждому результату наблюдению добавить
, то и
среднее арифметическое известно с той же точностью. Ведь возможна
систематическая ошибка - если к каждому результату наблюдению добавить ![]() , то и
среднее арифметическое увеличится на
, то и
среднее арифметическое увеличится на ![]() .
.
Поскольку
![]()
то в обозначениях предыдущего пункта
![]()
Следовательно, рациональный объем выборки равен
![]()
Для
практического использования полученной формулы надо оценить дисперсию
результатов наблюдений. Можно доказать, что, поскольку ![]() мало, это
можно сделать обычным способом, например, с помощью несмещенной выборочной
оценки дисперсии
мало, это
можно сделать обычным способом, например, с помощью несмещенной выборочной
оценки дисперсии
![]()
Здесь и далее рассуждения часто идут на двух уровнях. Первый - это уровень "истинных" случайных величин, обозначаемых "х", описывающих реальность, но неизвестных специалисту по анализу данных. Второй - уровень известных этому специалисту величин "у", отличающихся погрешностями от истинных. Погрешности малы, поэтому функции от х отличаются от функций от у на некоторые бесконечно малые величины. Эти соображения и позволяют использовать s2(y) как оценку D(x1).
Итак, выборочной оценкой рационального объема выборки является
![]()
Уже
на этом первом рассматриваемом примере видим, что рациональный объем выборки
находится не где-то вдали, а непосредственно рядом с теми объемами, с которыми
имеет дело любой практически работающий статистик. Например, если статистик
знает, что ![]() то nrat = 36. А именно такова погрешность
контрольных шаблонов во многих технологических процессах! Поэтому, занимаясь
управлением качеством, необходимо обращать внимание на действующую на
предприятии систему измерений.
то nrat = 36. А именно такова погрешность
контрольных шаблонов во многих технологических процессах! Поэтому, занимаясь
управлением качеством, необходимо обращать внимание на действующую на
предприятии систему измерений.
По
сравнению с классической математической статистикой доверительный интервал для
математического ожидания (для заданной доверительной вероятности ![]() ) имеет
другой вид:
) имеет
другой вид:
![]() (4)
(4)
где ![]() -
квантиль порядка (1+
-
квантиль порядка (1+ ![]() )/2
стандартного нормального распределения с математическим ожиданием 0 и
дисперсией 1..
)/2
стандартного нормального распределения с математическим ожиданием 0 и
дисперсией 1..
По поводу формулы (4)
была довольно жаркая дискуссия среди специалистов. Отмечалось, что она получена
на основе Центральной Предельной Теоремы теории вероятностей и может быть
использована при любом распределении результатов наблюдений (с конечной
дисперсией). Если же имеется дополнительная информация, то, по мнению отдельных
специалистов, формула (4) может быть уточнена. Например, если известно, что
распределение xi является нормальным, в качестве u(![]() ) целесообразно использовать квантиль распределения Стьюдента. К этому надо
добавить, что по небольшому числу наблюдений нельзя надежно установить
нормальность, а при росте объема выборки квантили распределения Стьюдента
приближаются к квантилям нормального распределения. Вопрос о том, часто ли
результаты наблюдений имеют нормальное распределение, подробно обсуждался среди
специалистов. Выяснилось, что распределения встречающихся в практических
задачах результатов измерений почти всегда отличны от нормальных [25]. А также
и от распределений из иных параметрических семейств, описываемых в учебниках.
) целесообразно использовать квантиль распределения Стьюдента. К этому надо
добавить, что по небольшому числу наблюдений нельзя надежно установить
нормальность, а при росте объема выборки квантили распределения Стьюдента
приближаются к квантилям нормального распределения. Вопрос о том, часто ли
результаты наблюдений имеют нормальное распределение, подробно обсуждался среди
специалистов. Выяснилось, что распределения встречающихся в практических
задачах результатов измерений почти всегда отличны от нормальных [25]. А также
и от распределений из иных параметрических семейств, описываемых в учебниках.
Применительно к оцениванию математического ожидания (но не к оцениванию других характеристик или параметров распределения) факт существования границы возможной точности, определяемой точностью исходных данных, не0днократно отмечался в литературе ([26, с.230-234], [31, с.121] и др.).
Пример 2. Оценивание дисперсии. Для статистики f(y) = s2(y), где s2(y) - выборочная дисперсия (несмещенная оценка теоретической дисперсии), при справедливости ограничений (1) на абсолютные погрешности имеем
![]()
Можно показать, что нотна Nf(y) сходится к
![]()
по вероятности с точностью до ![]() , когда n стремится к бесконечности. Это же предельное соотношение верно и для нотны Nf(х), вычисленной для исходных данных. Таким образом, в
данном случае справедлива формула (2) с
, когда n стремится к бесконечности. Это же предельное соотношение верно и для нотны Nf(х), вычисленной для исходных данных. Таким образом, в
данном случае справедлива формула (2) с
![]()
Известно, что случайная величина
![]()
является асимптотически нормальной с
математическим ожиданием 0 и дисперсией ![]()
Из
сказанного вытекает, что в статистике интервальных данных асимптотический
доверительный интервал для дисперсии ![]() (соответствующий доверительной вероятности
(соответствующий доверительной вероятности ![]() ) имеет
вид
) имеет
вид
![]()
где
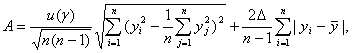
где ![]() обозначает
тот же самый квантиль стандартного нормального распределения, что и выше в
случае оценивания математического ожидания.
обозначает
тот же самый квантиль стандартного нормального распределения, что и выше в
случае оценивания математического ожидания.
Рациональный объем выборки при оценивании дисперсии равен
![]()
а выборочную оценку рационального
объема выборки ![]() можно вычислить, заменяя теоретические моменты на соответствующие выборочные и
используя доступные статистику результаты наблюдений, содержащие погрешности.
можно вычислить, заменяя теоретические моменты на соответствующие выборочные и
используя доступные статистику результаты наблюдений, содержащие погрешности.
Что
можно сказать о численной величине рационального объема выборки? Как и в случае
оценивания математического ожидания, она отнюдь не выходит за пределы обычно
используемых объемов выборок. Так, если распределение результатов наблюдений ![]() является нормальным с математическим ожиданием
0 и дисперсией
является нормальным с математическим ожиданием
0 и дисперсией ![]() , то в
результате вычисления моментов случайных величин в предыдущей формуле получаем,
что
, то в
результате вычисления моментов случайных величин в предыдущей формуле получаем,
что
![]()
где ![]() - отношение длины окружности к диаметру,
- отношение длины окружности к диаметру, ![]() Например, если
Например, если ![]() то
то ![]() Это меньше, чем при оценивании математического
ожидания в предыдущем примере.
Это меньше, чем при оценивании математического
ожидания в предыдущем примере.
Пример
3. Аддитивные статистики. Пусть ![]() - некоторая непрерывная функция. Аддитивные
статистики имеют вид
- некоторая непрерывная функция. Аддитивные
статистики имеют вид
![]()
Тогда
![]()
![]()
по вероятности при ![]() если
математические ожидания в правых частях двух последних соотношений существуют.
Применяя рассмотренные выше общие соображения, получаем, что при малых фиксированных
если
математические ожидания в правых частях двух последних соотношений существуют.
Применяя рассмотренные выше общие соображения, получаем, что при малых фиксированных ![]() и
и ![]() и достаточно больших n значения f(y) могут принимать любые величины из разрешенных
(например, записываемых заданным числом значащих цифр) в замкнутом интервале
и достаточно больших n значения f(y) могут принимать любые величины из разрешенных
(например, записываемых заданным числом значащих цифр) в замкнутом интервале
![]() (5)
(5)
при ограничениях (1) на абсолютные ошибки и в замкнутом интервале
![]() …(6)
…(6)
при ограничениях на относительные погрешности результатов наблюдений. Обратим внимание, что длины этих интервалов независимы от объема выборки, в частности, не стремятся к 0 при его росте.
К каким последствиям это приводит в задачах статистического оценивания? Поскольку для статистик аддитивного типа
![]() (7)
(7)
по вероятности при ![]() если математическое ожидание в правой части
формулы (7) существует, то аддитивную статистику f(x) естественно рассматривать как непараметрическую
оценку этого математического ожидания. Термин «непараметрическая» означает, что
не делается предположений о принадлежности функции распределения выборки к тому
или иному параметрическому семейству распределения. Распределение статистики f(x) зависит от распределения результатов наблюдений.
Однако для любого распределения результатов наблюдений с конечной дисперсией
статистика f(x) является состоятельной и асимптотически нормальной
оценкой для математического ожидания, указанного в правой части формулы (7).
если математическое ожидание в правой части
формулы (7) существует, то аддитивную статистику f(x) естественно рассматривать как непараметрическую
оценку этого математического ожидания. Термин «непараметрическая» означает, что
не делается предположений о принадлежности функции распределения выборки к тому
или иному параметрическому семейству распределения. Распределение статистики f(x) зависит от распределения результатов наблюдений.
Однако для любого распределения результатов наблюдений с конечной дисперсией
статистика f(x) является состоятельной и асимптотически нормальной
оценкой для математического ожидания, указанного в правой части формулы (7).
Как
известно, в рамках классической математической статистики в предположении
существования ненулевой дисперсии Dg(x1) в силу асимптотической нормальности аддитивной
статистики f(x) асимптотический доверительный интервал,
соответствующий доверительной вероятности ![]() , имеет
вид
, имеет
вид
![]()
где s(g(x)) – выборочное среднее квадратическое отклонение,
построенное по g(x1), g(x2),…, g(xn), а ![]() -
квантиль стандартного нормального распределения порядка
-
квантиль стандартного нормального распределения порядка ![]()
В рассматриваемой модели порождения интервальных данных вместо f(x) необходимо использовать f(y), а вместо g(xi) – соответственно g(yi), i-1,2,…,n. При этом доверительный интервал необходимо расширить с учетом формул (5) и (6).
В соответствии с проведенными рассуждениями для аддитивных статистик асимптотическая нотна имеет вид
![]()
при ограничениях (1) на абсолютную погрешность и
![]()
при ограничениях на относительную погрешность. В первом случае нотна является обобщением понятия предельной абсолютной систематической ошибки, во втором – предельной относительной систематической ошибки. Отметим, что, как и в примерах 1 и 2, асимптотическая нотна не зависит от точки, в которой вычисляется. Таким образом, она является константой для конкретного метода статистического анализа данных.
Поскольку n велико, а ![]() и
и ![]() малы, то можно пренебречь отличием выборочного
среднего квадратического отклонения s(g(y)), вычисленного по выборке преобразованных значений
малы, то можно пренебречь отличием выборочного
среднего квадратического отклонения s(g(y)), вычисленного по выборке преобразованных значений ![]() , от выборочного среднего
квадратического отклонения s(g(x)), построенного по выборке
, от выборочного среднего
квадратического отклонения s(g(x)), построенного по выборке ![]() Разность этих двух величин является бесконечно
малой, они приближаются к одной и той же положительной константе.
Разность этих двух величин является бесконечно
малой, они приближаются к одной и той же положительной константе.
В статистике интервальных данных выборочный доверительный интервал для Mg(x1) имеет вид
![]()
В асимптотике его длина такова:
![]() (8)
(8)
где ![]() - дисперсия g(x1), в то время как в классической теории математической
статистики имеется только второе слагаемое. Соотношение (8) – аналог суммарной
ошибки у метрологов [26]. Поскольку первое слагаемое положительно, то
оценивание Mg(x1) с помощью f(y) не является состоятельным.
- дисперсия g(x1), в то время как в классической теории математической
статистики имеется только второе слагаемое. Соотношение (8) – аналог суммарной
ошибки у метрологов [26]. Поскольку первое слагаемое положительно, то
оценивание Mg(x1) с помощью f(y) не является состоятельным.
Для аддитивных статистик при больших n максимум (по возможным погрешностям) среднего квадрата отклонения оценки имеет вид
![]() (9)
(9)
с точностью до членов более высокого
порядка. Исходя из принципа уравнивания погрешностей в общей схеме устойчивости
[3], нецелесообразно второе слагаемое в (9) делать меньше первого за счет
увеличения объема выборки n. Рациональный объем выборки, т.е. тот объем, при
котором равны погрешности оценивания (или проверки гипотез), вызванные
погрешностями исходных данных, и статистические погрешности, рассчитанные по
обычным правилам математической статистики (при ![]() ), для
аддитивных статистик согласно (9) имеет вид
), для
аддитивных статистик согласно (9) имеет вид
![]() (10)
(10)
В
качестве примера рассмотрим экспоненциально распределенные результаты
наблюдений ![]() Оцениваем математическое ожидание с помощью
выборочного среднего арифметического при ограничениях на относительную
погрешность. Тогда согласно формуле (10)
Оцениваем математическое ожидание с помощью
выборочного среднего арифметического при ограничениях на относительную
погрешность. Тогда согласно формуле (10)
![]()
В частности, если относительная
погрешность измерений ![]() =10%, то
рациональный объем выборки равен 100. Формуле (10) соответствует также
рассмотренный выше пример 1.
=10%, то
рациональный объем выборки равен 100. Формуле (10) соответствует также
рассмотренный выше пример 1.
Пример 4. Оценивание медианы распределения с помощью выборочной медианы. Хотя нельзя выделить главный линейный член из-за недифференцируемости функции f(x), выражающей выборочную медиану через элементы выборки, непосредственно из определения нотны следует, что при ограничениях на абсолютные погрешности
![]() ,
,
а при ограничениях на относительные погрешности
![]()
с точностью до бесконечно малых более
высокого порядка, где ![]() - теоретическая медиана. Доверительный
интервал для медианы имеет вид
- теоретическая медиана. Доверительный
интервал для медианы имеет вид
![]() ,
,
где ![]() - доверительный интервал для медианы,
вычисленный по классическим правилам непараметрической статистики [27]. Для
нахождения рационального объема выборки можно использовать асимптотическую
дисперсию выборочной медианы. Она, как известно (см., например, [28, с.178]), равна
- доверительный интервал для медианы,
вычисленный по классическим правилам непараметрической статистики [27]. Для
нахождения рационального объема выборки можно использовать асимптотическую
дисперсию выборочной медианы. Она, как известно (см., например, [28, с.178]), равна
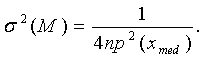
где ![]() - плотность распределения результатов
измерений в точке
- плотность распределения результатов
измерений в точке ![]() .
Следовательно, рациональный объем выборки имеет вид
.
Следовательно, рациональный объем выборки имеет вид
![]()
при ограничениях на абсолютные и относительные погрешности результатов измерений соответственно. Для практического использования этих формул следует оценить плотность распределения результатов измерений в одной точке - теоретической медиане. Это можно сделать с помощью тех или иных непараметрических оценок плотности [27].
Если результаты наблюдений имеют стандартное нормальное распределение с математическим ожиданием 0 и дисперсией 1, то
![]()
В этом случае рациональный объем
выборки в ![]() раз больше, чем для оценивания математического
ожидания (пример 1 выше). Однако для других распределений рассматриваемое
соотношение объемов может быть иным, в частности, меньше 1. Как вытекает из
статьи А.Н.Колмогорова 1931 г. [29], рассматриваемое соотношение объемов может
принимать любое значение между 0 и3.
раз больше, чем для оценивания математического
ожидания (пример 1 выше). Однако для других распределений рассматриваемое
соотношение объемов может быть иным, в частности, меньше 1. Как вытекает из
статьи А.Н.Колмогорова 1931 г. [29], рассматриваемое соотношение объемов может
принимать любое значение между 0 и3.
Пример 5. Оценивание коэффициента вариации. Рассмотрим выборочный коэффициент вариации
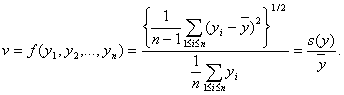
Как нетрудно подсчитать,
![]()
В случае ограничений на относительную погрешность
![]()
На основе этого предельного соотношения и формулы для асимптотической дисперсии выборочного коэффициента вариации, приведенной в [27], могут быть найдены по описанной выше схеме доверительные границы для теоретического коэффициента вариации и рациональный объем выборки.
Замечание. Отметим, что формулы для рационального объема выборки получены на основе асимптотической теории, а применяются для получения конечных объемов – 36 и 100 в примерах 1-3. Как всегда при использовании асимптотических результатов математической статистики, необходимы дополнительные исследования для изучения точности асимптотических формул при конечных объемах выборок.
Рассмотрим
классическую в прикладной математической статистике параметрическую задачу
оценивания. Исходные данные – выборка считаются
наборомx1, x2,
..., xn, состоящая
из n действительных
чисел. В вероятностной модели простой случайной выборки ее элементы x1, x2, ..., xn реализаций n независимых
одинаково распределенных случайных величин. Будем считать, что эти величины
имеют плотность f(x). В параметрической
статистической теории предполагается, что плотность f(x) известна с
точностью до конечномерного параметра, т.е.,при некотором ![]() Это, конечно,
весьма сильное предположение, которое требует обоснования и проверки однако в
настоящее
Это, конечно,
весьма сильное предположение, которое требует обоснования и проверки однако в
настоящее
время параметрическая теория оценивания широко используется в
различных прикладных областях.
Все результаты наблюдений определяются с некоторой точностью, в частности, записываются с помощью конечного числа значащих цифр (обычно 2 – 5). Следовательно, все реальные распределения результатов наблюдений дискретны. Обычно считают, что эти дискретные распределения достаточно хорошо приближаются непрерывными. Уточняя это утверждение, приходим к уже рассматривавшейся модели, согласно которой статистику доступны лишь величины
yj = xj + ![]() j , j = 1, 2, ... , n ,
j , j = 1, 2, ... , n ,
где xi – «истинные» значения, ![]() погрешности наблюдений (включая погрешности
дискретизации). В вероятностной модели принимаем, что n пар
погрешности наблюдений (включая погрешности
дискретизации). В вероятностной модели принимаем, что n пар
![]()
образуют простую случайную выборку из
некоторого двумерного распределения, причем x1, x2,
..., xn - выборка из распределения с плотностью ![]() . Необходимо
учитывать, что
. Необходимо
учитывать, что ![]() и
и ![]() - реализации зависимых случайных величин (если
считать их независимыми, то распределение yi будет непрерывным, а не дискретным). Поскольку
систематическую ошибку, как правило, нельзя полностью исключить [26, с.141], то
необходимо рассматривать случай
- реализации зависимых случайных величин (если
считать их независимыми, то распределение yi будет непрерывным, а не дискретным). Поскольку
систематическую ошибку, как правило, нельзя полностью исключить [26, с.141], то
необходимо рассматривать случай ![]() Нет оснований
априори принимать и нормальность распределения погрешностей (согласно сводкам
экспериментальных данных о разнообразии форм распределения погрешностей
измерений, приведенным в [26, с.148] и [27, с.71-77], в подавляющем большинстве
случаев гипотеза о нормальном распределении погрешностей оказалась неприемлемой
для средств измерений различных типов). Таким образом, все три распространенных
представления о свойствах погрешностей не адекватны реальности. Влияние
погрешностей наблюдений на свойства статистических моделей необходимо изучать
на основе иных моделей, а именно, моделей интервальной статистики.
Нет оснований
априори принимать и нормальность распределения погрешностей (согласно сводкам
экспериментальных данных о разнообразии форм распределения погрешностей
измерений, приведенным в [26, с.148] и [27, с.71-77], в подавляющем большинстве
случаев гипотеза о нормальном распределении погрешностей оказалась неприемлемой
для средств измерений различных типов). Таким образом, все три распространенных
представления о свойствах погрешностей не адекватны реальности. Влияние
погрешностей наблюдений на свойства статистических моделей необходимо изучать
на основе иных моделей, а именно, моделей интервальной статистики.
Пусть ![]() - характеристика величины погрешности,
например, средняя квадратическая ошибка
- характеристика величины погрешности,
например, средняя квадратическая ошибка ![]() . В
классической математической статистике
. В
классической математической статистике ![]() считается пренебрежимо малой (
считается пренебрежимо малой (![]() ) при
фиксированном объеме выборки n. Общие результаты доказываются в асимптотике
) при
фиксированном объеме выборки n. Общие результаты доказываются в асимптотике ![]() . Таким
образом, в классической математической статистике сначала делается предельный
переход
. Таким
образом, в классической математической статистике сначала делается предельный
переход ![]() , а затем
предельный переход
, а затем
предельный переход ![]() . В
статистике интервальных данных принимаем, что объем выборки достаточно велик (
. В
статистике интервальных данных принимаем, что объем выборки достаточно велик (![]() ), но
всем измерениям соответствует одна и та же характеристика погрешности
), но
всем измерениям соответствует одна и та же характеристика погрешности ![]() .
Полезные для анализа реальных данных предельные теоремы получаем при
.
Полезные для анализа реальных данных предельные теоремы получаем при ![]() . В
статистике интервальных данных сначала делается предельный переход
. В
статистике интервальных данных сначала делается предельный переход ![]() , а затем
предельный переход
, а затем
предельный переход ![]() . Итак, в
обеих теориях используются одни и те же два предельных перехода:
. Итак, в
обеих теориях используются одни и те же два предельных перехода: ![]() и
и ![]() , но в
разном порядке. Утверждения обеих теорий принципиально различны.
, но в
разном порядке. Утверждения обеих теорий принципиально различны.
В дальнейшем изложение идет на примере оценивания параметров гамма-распределения, хотя аналогичные результаты можно получить и для других параметрических семейств, а также для задач проверки гипотез (см. ниже) и т.д. Наша цель – продемонстрировать основные черты подхода статистики интервальных данных. Его разработка была стимулирована подготовкой ГОСТ 11.011-83 [4].
Отметим,
что постановки статистики объектов нечисловой природы соответствуют подходу,
принятому в общей теории устойчивости [3,27]. В соответствии с этим подходом
выборке x = (x1,
x2, ..., xn) ставится в соответствие множество
допустимых отклонений G(x), т.е. множество возможных значений вектора результатов
наблюдений y = (y1, y2, ..., yn). Если известно, что абсолютная
погрешность результатов измерений не превосходит ![]() , то
множество допустимых отклонений имеет вид
, то
множество допустимых отклонений имеет вид
![]()
Если известно, что относительная
погрешность не превосходит ![]() , то
множество допустимых отклонений имеет вид
, то
множество допустимых отклонений имеет вид
![]()
Теория устойчивости позволяет учесть «наихудшие» отклонения, т.е. приводит к выводам типа минимаксных, в то время как конкретные модели погрешностей позволяют делать заключения о поведении статистик «в среднем».
Оценки параметров гамма-распределения. Как известно, случайная величина Х имеет гамма-распределение, если ее плотность такова [4]:

где a – параметр формы, b – параметр масштаба, ![]() - гамма-функция. Отметим, что есть и иные
способы параметризации семейства гамма-распределений [30].
- гамма-функция. Отметим, что есть и иные
способы параметризации семейства гамма-распределений [30].
Поскольку M(X) = ab, D(X) = ab2, то оценки метода имеют вид
![]()
где ![]() - выборочное среднее арифметическое, а s2 – выборочная дисперсия. Можно
показать, что при больших n
- выборочное среднее арифметическое, а s2 – выборочная дисперсия. Можно
показать, что при больших n
![]() (11)
(11)
с точностью до бесконечно малых более высокого порядка.
Оценка максимального правдоподобия a* имеет вид [4]:
![]() (12)
(12)
где ![]() - функция, обратная к функции
- функция, обратная к функции
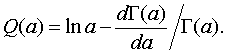
При больших n с точностью до бесконечно малых более высокого порядка
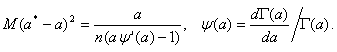
Как и для оценок метода моментов, оценка максимального правдоподобия b* параметра масштаба имеет вид
![]()
При больших n с точностью до бесконечно малых более высокого порядка
![]()
Используя свойства гамма-функции, можно показать [4], что при больших а
![]()
с точностью до бесконечно малых более высокого порядка. Сравнивая с формулами (11), убеждаемся в том, что средние квадраты ошибок для оценок метода моментов больше соответствующих средних квадратов ошибок для оценок максимального правдоподобия. Таким образом, с точки зрения классической математической статистики оценки максимального правдоподобия имеют преимущество по сравнению с оценками метода моментов.
Необходимость учета погрешностей измерений. Положим
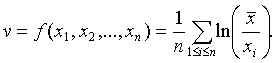
Из свойств функции ![]() следует [4, с.14], что при малых v
следует [4, с.14], что при малых v
![]() (13)
(13)
В силу состоятельности оценки
максимального правдоподобия a* из формулы (13) следует, что ![]() по вероятности при
по вероятности при ![]()
Согласно модели статистики интервальных данных результатами наблюдений являются не xi, а yi, вместо v по реальным данным рассчитывают
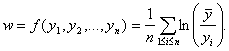
Имеем
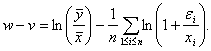 (14)
(14)
В силу закона больших чисел при
достаточно малой погрешности ![]() ,
обеспечивающей возможность приближения
,
обеспечивающей возможность приближения ![]() для слагаемых в формуле (14), или, что
эквивалентно, при достаточно малых предельной абсолютной погрешности
для слагаемых в формуле (14), или, что
эквивалентно, при достаточно малых предельной абсолютной погрешности ![]() в формуле (1) или достаточно малой предельной
относительной погрешности
в формуле (1) или достаточно малой предельной
относительной погрешности ![]() имеем при
имеем при ![]()
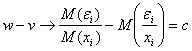
по вероятности (в предположении, что
все погрешности одинаково распределены). Таким образом, наличие погрешностей
вносит сдвиг, вообще говоря, не исчезающий при росте объема выборки.
Следовательно, если ![]() то оценка максимального правдоподобия не является
состоятельной. Имеем
то оценка максимального правдоподобия не является
состоятельной. Имеем
![]()
где величина a*(y) определена по формуле (12) с заменой xi на yi, i=1,2,…,n. Из формулы (13) следует [4], что
![]() (15)
(15)
т.е. влияние погрешностей измерений увеличивается по мере роста а.
Из формул для v и w следует, что с точностью до бесконечно малых более высокого порядка
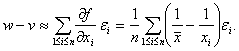 (16)
(16)
С целью нахождения асимптотического распределения w выделим, используя формулу (16) и формулу для v, главные члены в соответствующих слагаемых
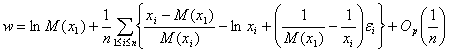 . (17)
. (17)
Таким образом, величина w представлена в виде суммы
независимых одинаково распределенных случайных величин (с точностью до
зависящего от случая остаточного члена порядка 1/n). В каждом слагаемом выделяются две
части – одна, соответствующая Мб и вторая, в которую входят ![]() На основе представления (17) можно показать,
что при
На основе представления (17) можно показать,
что при ![]() распределения случайных величин v и w асимптотически нормальны, причем
распределения случайных величин v и w асимптотически нормальны, причем
![]()
Из асимптотического
совпадения дисперсий v и w, вида параметров асимптотического распределения (при ![]() ) оценки
максимального правдоподобия a* и формулы (15) вытекает одно из основных соотношений
статистики интервальных данных
) оценки
максимального правдоподобия a* и формулы (15) вытекает одно из основных соотношений
статистики интервальных данных
![]() (18)
(18)
Соотношение (18) уточняет утверждение о несостоятельности a*. Из него следует также, что не имеет смысла безгранично увеличивать объем выборки n с целью повышения точности оценивания параметра а, поскольку при этом уменьшается только второе слагаемое в (18), а первое остается постоянным.
В соответствии с общим подходом статистики интервальных данных в стандарте [4] предлагается определять рациональный объем выборки nrat определять из условия «уравнивания погрешностей» (это условие было впервые предложено в монографии [3]) различных видов в формуле (18), т.е. из условия
![]()
Упрощая это уравнение в предположении ![]() получаем, что
получаем, что
![]()
Согласно сказанному выше,
целесообразно использовать лишь выборки с объемами ![]() . Превышение рационального объема выборки
. Превышение рационального объема выборки ![]() не дает существенного повышения точности
оценивания.
не дает существенного повышения точности
оценивания.
Применение методов теории устойчивости. Найдем асимптотическую нотну. Как следует из вида главного линейного члена в формуле (17), решение оптимизационной задачи
![]()
соответствующей ограничениям на абсолютные погрешности, имеет вид

Однако при этом пары ![]() не образуют простую случайную выборку, т.к. в
выражения для
не образуют простую случайную выборку, т.к. в
выражения для ![]() входит
входит ![]() . Однако
при
. Однако
при ![]() можно заменить
можно заменить ![]() на М(х1). Тогда получаем,
что
на М(х1). Тогда получаем,
что
![]()
при a>1, где

Таким образом, с точностью до бесконечно малых более высокого порядка нотна имеет вид
![]()
Применим полученные
результаты к построению доверительных интервалов. В постановке классической
математической статистики (т.е. при ![]() )
доверительный интервал для параметра формы а, соответствующий
доверительной вероятности
)
доверительный интервал для параметра формы а, соответствующий
доверительной вероятности ![]() , имеет
вид [4]
, имеет
вид [4]
![]()
где ![]() - квантиль порядка
- квантиль порядка ![]() стандартного нормального распределения с
математическим ожиданием 0 и дисперсией 1,
стандартного нормального распределения с
математическим ожиданием 0 и дисперсией 1,
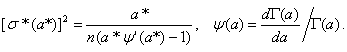
В постановке статистики интервальных
данных (т.е. при ![]() ) следует
рассматривать доверительный интервал
) следует
рассматривать доверительный интервал
![]()
где
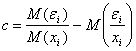
в вероятностной постановке (пары ![]() образуют простую случайную выборку) и
образуют простую случайную выборку) и ![]() в оптимизационной постановке. Как в
вероятностной, так и в оптимизационной постановках длина доверительного
интервала не стремится к 0 при
в оптимизационной постановке. Как в
вероятностной, так и в оптимизационной постановках длина доверительного
интервала не стремится к 0 при ![]()
Если
ограничения наложены на предельную относительную погрешность, задана величина ![]() , то
значение с можно найти с помощью следующих правил приближенных
вычислений [32, с.142].
, то
значение с можно найти с помощью следующих правил приближенных
вычислений [32, с.142].
(I). Относительная погрешность суммы заключена между наибольшей и наименьшей из относительных погрешностей слагаемых.
(II). Относительная погрешность произведения и частного равна сумме относительных погрешностей сомножителей или, соответственно, делимого и делителя.
Можно показать, что в
рамках статистики интервальных данных с ограничениями на относительную
погрешность правила (I) и (II) являются строгими утверждениями при ![]()
Обозначим относительную погрешность некоторой величины t через ОП(t), абсолютную погрешность – через АП(t).
Из
правила (I) следует, что ОП(![]() ) =
) = ![]() , а из
правила (II) – что
, а из
правила (II) – что
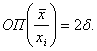
Поскольку рассмотрения ведутся при ![]() то в силу неравенства Чебышева
то в силу неравенства Чебышева
![]() (19)
(19)
по вероятности при ![]() поскольку и числитель, и знаменатель в (19) с
близкой к 1 вероятностью лежат в промежутке
поскольку и числитель, и знаменатель в (19) с
близкой к 1 вероятностью лежат в промежутке ![]() где константа d может быть определена с помощью
упомянутого неравенства Чебышева.
где константа d может быть определена с помощью
упомянутого неравенства Чебышева.
Поскольку при справедливости (19) с точностью до бесконечно малых более высокого порядка
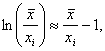
то с помощью трех последних соотношений имеем
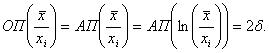 (20)
(20)
Применим еще одно правило приближенных вычислений [32, с.142].
(III). Предельная абсолютная погрешность суммы равна сумме предельных абсолютных погрешностей слагаемых.
Из (20) и правила (III) следует, что
![]() (21)
(21)
Из (15) и (21) вытекает [4, с.44, ф-ла (18)], что
![]()
откуда в соответствии с ранее полученной
формулой для рационального объема выборки с заменой ![]() получаем, что
получаем, что
![]()
В частности, при a = 5,00, ![]() = 0,01 получаем
= 0,01 получаем ![]() т.е. в ситуации, в которой были получены
данные о наработке резцов до предельного состояния (см. табл.1, составленную
согласно [4, с.29]), проводить более 50 наблюдений нерационально.
т.е. в ситуации, в которой были получены
данные о наработке резцов до предельного состояния (см. табл.1, составленную
согласно [4, с.29]), проводить более 50 наблюдений нерационально.
Таблица 1.
Наработка резцов до предельного состояния, ч
№ п/п |
Наработка, ч |
№ п/п |
Наработка, ч |
№ п/п |
Наработка, ч |
1 |
9 |
18 |
47,5 |
35 |
63 |
2 |
17,5 |
19 |
48 |
36 |
64,5 |
3 |
21 |
20 |
50 |
37 |
65 |
4 |
26,5 |
21 |
51 |
38 |
67,5 |
5 |
27,5 |
22 |
53,5 |
39 |
68,5 |
6 |
31 |
23 |
55 |
40 |
70 |
7 |
32,5 |
24 |
56 |
41 |
72,5 |
8 |
34 |
25 |
56 |
42 |
77,5 |
9 |
36 |
26 |
56,5 |
43 |
81 |
10 |
36,5 |
27 |
57,5 |
44 |
82,5 |
11 |
39 |
28 |
58 |
45 |
90 |
12 |
40 |
29 |
59 |
46 |
96 |
13 |
41 |
30 |
59 |
47 |
101,5 |
14 |
42,5 |
31 |
60 |
48 |
117,5 |
15 |
43 |
32 |
61 |
49 |
127,5 |
16 |
45 |
33 |
61,5 |
50 |
130 |
17 |
46 |
34 |
62 |
В
соответствии с ранее проведенными рассмотрениями асимптотический доверительный
интервал для a, соответствующий доверительной вероятности ![]() = 0,95, имеет вид
= 0,95, имеет вид
![]()
В частности, при ![]() имеем асимптотический доверительный интервал
[2,12; 7,86] вместо [3,14; 6,86] при
имеем асимптотический доверительный интервал
[2,12; 7,86] вместо [3,14; 6,86] при ![]()
При больших а в силу соображений, приведенных при выводе формулы (19), можно связать между собой относительную и абсолютную погрешности результатов наблюдений xi :
![]() (21)
(21)
Следовательно, при больших а имеем
![]()
Таким образом, проведенные рассуждения дали возможность вычислить асимптотику интеграла, задающего величину А.
Сравнение
методов оценивания. Изучим влияние погрешностей измерений (с ограничениями
на абсолютную погрешность) на оценку ![]() метода моментов. Имеем
метода моментов. Имеем
![]()
Погрешность s2 зависит от способа вычисления s2. Если используется формула
![]() (22)
(22)
то необходимо использовать соотношения
![]()
По сравнению с анализом влияния
погрешностей на оценку а* здесь возникает новый момент – необходимость учета
погрешностей в случайной составляющей отклонения оценки ![]() от оцениваемого параметра, в то время как при
рассмотрении оценки максимального правдоподобия погрешности давали лишь
смещение. Примем в соответствии с неравенством Чебышева
от оцениваемого параметра, в то время как при
рассмотрении оценки максимального правдоподобия погрешности давали лишь
смещение. Примем в соответствии с неравенством Чебышева
![]() (23)
(23)
тогда
![]()
Если вычислять s2 по формуле
![]() (24)
(24)
то аналогичные вычисления дают, что
![]()
т.е. погрешность при больших а существенно больше. Хотя правые части формул (22) и (24) тождественно равны, но погрешности вычислений по этим формулам весьма отличаются. Связано это с тем, что в формуле (24) последняя операция – нахождение разности двух больших чисел, примерно равных по величине (для выборки из гамма-распределения при большом значении параметра формы).
Из полученных результатов следует, что
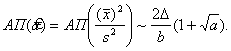
При выводе этой формулы использована линеаризация влияния погрешностей (выделение главного линейного члена). Используя связь (21) между абсолютной и относительной погрешностями, можно записать
![]()
Эта формула отличается от приведенной в [4, с.44, ф-ла (19)]
![]()
поскольку в [4] вместо (23) использовалась оценка
![]()
Используя соотношение (23), мы характеризуем влияние погрешностей «в среднем».
Доверительный интервал, соответствующий доверительной вероятности 0,95, имеет вид
![]()
Если ![]() то получаем доверительный интервал [2,54;
7,46] вместо [2,86; 7,14] при
то получаем доверительный интервал [2,54;
7,46] вместо [2,86; 7,14] при ![]() Хотя при
Хотя при ![]() доверительный интервал для a при использовании оценки метода
моментов
доверительный интервал для a при использовании оценки метода
моментов ![]() шире, чем при использовании оценки
максимального правдоподобия а*, при
шире, чем при использовании оценки
максимального правдоподобия а*, при ![]() результат сравнения длин интервалов
противоположен.
результат сравнения длин интервалов
противоположен.
Необходимо
выбрать способ сравнения двух методов оценивания параметра а, поскольку
в длины доверительных интервалов входят две составляющие – зависящая от
доверительной вероятности и не зависящая от нее. Выберем ![]() т.е.
т.е. ![]() Тогда оценке максимального правдоподобия а* соответствует полудлина доверительного интервала
Тогда оценке максимального правдоподобия а* соответствует полудлина доверительного интервала
![]() (25)
(25)
а оценке ![]() метода моментов соответствует полудлина
доверительного интервала
метода моментов соответствует полудлина
доверительного интервала
![]() (26)
(26)
Ясно, что больших а или
больших n справедливо неравенство ![]() т.е. метод моментов лучше метода максимального
правдоподобия, вопреки классическим результатам Р.Фишера при
т.е. метод моментов лучше метода максимального
правдоподобия, вопреки классическим результатам Р.Фишера при ![]() [33,с.99].
[33,с.99].
Из (25) и (26) элементарными преобразованиями получаем следующее правило принятия решений. Если
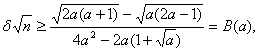
то ![]() и следует использовать
и следует использовать ![]() ; а если
; а если ![]() то
то ![]() и надо применять а*. Для выбора метода
оценивания при обработке реальных данных целесообразно использовать
и надо применять а*. Для выбора метода
оценивания при обработке реальных данных целесообразно использовать ![]() (см. раздел 5 в ГОСТ 11.011-83 [4, с.10-11]).
(см. раздел 5 в ГОСТ 11.011-83 [4, с.10-11]).
Пример анализа реальных данных опубликован в [4].
На основе рассмотрения проблем оценивания параметров гамма-распределения можно сделать некоторые общие выводы. Если в классической теории математической статистики:
а) существуют состоятельные оценки an параметра а,
![]()
б) для повышения точности оценивания объем выборки целесообразно безгранично увеличивать;
в) оценки максимального правдоподобия лучше оценок метода моментов,
то в статистике интервальных данных, учитывающей погрешности измерений, соответственно:
а) не существует состоятельных оценок: для любой оценки an существует константа с такая, что
![]()
б)
не имеет смысла рассматривать объемы выборок, большие «рационального объема
выборки» ![]()
в)
оценки метода моментов в обширной области параметров ![]() лучше оценок максимального правдоподобия, в
частности, при
лучше оценок максимального правдоподобия, в
частности, при ![]() и при
и при ![]()
Ясно, что приведенные выше результаты справедливы не только для рассмотренной задачи оценивания параметров гамма-распределения, но и для многих других постановок прикладной математической статистики.
Метрологические,
методические, статистические и вычислительные погрешности. Целесообразно
выделить ряд видов погрешностей статистических данных. Погрешности, вызванные
неточностью измерения исходных данных, называем метрологическими. Их
максимальное значение можно оценить с помощью нотны. Впрочем, выше на примере
оценивания параметров гамма-распределения показано, что переход от
максимального отклонения к реально имеющемуся в вероятностно-статистической
модели не меняет выводы (с точностью до умножения предельных значений
погрешностей ![]() или
или ![]() на константы). Как правило, метрологические
погрешности не убывают с ростом объема выборки.
на константы). Как правило, метрологические
погрешности не убывают с ростом объема выборки.
Методические погрешности вызваны неадекватностью вероятностно-статистической модели, отклонением реальности от ее предпосылок. Неадекватность обычно не исчезает при росте объема выборки. Методические погрешности целесообразно изучать с помощью «общей схемы устойчивости» [3,27], обобщающей популярную в теории робастных статистических процедур модель засорения большими выбросами. В настоящей главе методические погрешности не рассматриваются.
Статистическая погрешность – это та погрешность, которая традиционно рассматривается в математической статистике. Ее характеристики – дисперсия оценки, дополнение до 1 мощности критерия при фиксированной альтернативе и т.д. Как правило, статистическая погрешность стремится к 0 при росте объема выборки.
Вычислительная погрешность определяется алгоритмами расчета, в частности, правилами округления. На уровне чистой математики справедливо тождество правых частей формул (22) и (24), задающих выборочную дисперсию s2, а на уровне вычислительной математики формула (22) дает при определенных условиях существенно больше верных значащих цифр, чем вторая [34, с.51-52].
Выше на примере задачи оценивания параметров гамма-распределения рассмотрено совместное действие метрологических и вычислительных погрешностей, причем погрешности вычислений оценивались по классическим правилам для ручного счета [32]. Оказалось, что при таком подходе оценки метода моментов имеют преимущество перед оценками максимального правдоподобия в обширной области изменения параметров. Однако, если учитывать только метрологические погрешности, как это делалось выше в примерах 1-5, то с помощью аналогичных выкладок можно показать, что оценки этих двух типов имеют (при достаточно больших n) одинаковую погрешность.
Вычислительную погрешность здесь подробно не рассматриваем. Ряд интересных результатов о ее роли в статистике получили Н.Н.Ляшенко и М.С.Никулин [35].
Проведем сравнение методов оценивания параметров в более общей постановке.
В теории оценивания параметров классической математической статистики установлено, что метод максимального правдоподобия, как правило, лучше (в смысле асимптотической дисперсии асимптотического среднего квадрата ошибки), чем метод моментов. Однако в интервальной статистике это, вообще говоря, не так, что продемонстрировано выше на примере оценивания параметров гамма-распределения. Сравним эти два метода оценивания в случае интервальных данных в общей постановке. Поскольку метод максимального правдоподобия – частный случай метода минимального контраста, начнем с разбора этого несколько более общего метода.
Оценки
минимального контраста. Пусть Х – пространство, в котором лежат
независимые одинаково распределенные случайные элементы ![]() Будем оценивать элемент пространства
параметров
Будем оценивать элемент пространства
параметров ![]() с помощью функции контраста
с помощью функции контраста ![]() Оценкой минимального контраста называется
Оценкой минимального контраста называется
![]()
Если множество ![]() состоит из более чем одного элемента, то
оценкой минимального контраста называют также любой элемент
состоит из более чем одного элемента, то
оценкой минимального контраста называют также любой элемент ![]() .
.
Оценками
минимального контраста являются, в частности, многие робастные статистики
[3,36]. Эти оценки широко используются в статистике объектов нечисловой природы
[3,27], поскольку при ![]() переходят в переходят в эмпирические средние,
а если
переходят в переходят в эмпирические средние,
а если ![]() - пространство бинарных отношений – в медиану
Кемени.
- пространство бинарных отношений – в медиану
Кемени.
Пусть
в Х имеется мера ![]() (заданная на той же
(заданная на той же ![]() -алгебре,
что участвует в определении случайных элементов xi ), и
-алгебре,
что участвует в определении случайных элементов xi ), и ![]() - плотность распределения xi по мере
- плотность распределения xi по мере ![]() . Если
. Если
![]()
то оценка минимального контраста переходит в оценку максимального правдоподобия.
Асимптотическое
поведение оценок минимального контраста в случае пространств Х и ![]() общего вида хорошо изучено [37], в частности,
известны условия состоятельности оценок. Здесь ограничимся случаем X = R1, но при этом введя погрешности
измерений
общего вида хорошо изучено [37], в частности,
известны условия состоятельности оценок. Здесь ограничимся случаем X = R1, но при этом введя погрешности
измерений ![]() Примем также, что
Примем также, что ![]()
В
рассматриваемой математической модели предполагается, что статистику известны
лишь искаженные значения ![]() Поэтому вместо
Поэтому вместо ![]() он вычисляет
он вычисляет
![]()
Будем
изучать величину ![]() в предположении, что погрешности измерений
в предположении, что погрешности измерений ![]() малы. Цель этого изучения – продемонстрировать
идеи статистики интервальных данных при достаточно простых предположениях.
Поэтому естественно следовать условиям и ходу рассуждений, которые обычно
принимаются при изучении оценок максимального правдоподобия [38, п.33.3].
малы. Цель этого изучения – продемонстрировать
идеи статистики интервальных данных при достаточно простых предположениях.
Поэтому естественно следовать условиям и ходу рассуждений, которые обычно
принимаются при изучении оценок максимального правдоподобия [38, п.33.3].
Пусть ![]() - истинное значение параметра, функция
- истинное значение параметра, функция ![]() трижды дифференцируема по
трижды дифференцируема по ![]() , причем
, причем
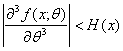
при всех ![]() Тогда
Тогда
![]() (27)
(27)
где ![]()
Используя обозначения векторов x = (x1 , x2 , ..., xn ), y = (y1 , y2 , ..., yn ), введем суммы
![]()
Аналогичным образом введем функции B0(y), B1(y), R(y), в которых вместо xi стоят yi, i=1,2,…,n.
Поскольку
в соответствии с теоремой Ферма оценка минимального контраста ![]() удовлетворяет уравнению
удовлетворяет уравнению
![]() (28)
(28)
то, подставляя в (27) xi вместо x и суммируя по i = 1,2,…,n, получаем, что
![]() (29)
(29)
откуда
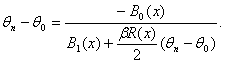 (30)
(30)
Решения уравнения (28) будем также называть оценками минимального контраста. Хотя уравнение (28) – лишь необходимое условие минимума, такое словоупотребление не будет вызывать трудностей.
Теорема
1. Пусть для любого x выполнено соотношение (27). Пусть для случайной
величины х1 с распределением, соответствующим значению
параметра ![]() существуют математические ожидания
существуют математические ожидания
![]() (31)
(31)
Тогда существуют оценки минимального
контраста ![]() такие, что
такие, что ![]() при
при ![]() (в смысле сходимости по вероятности).
(в смысле сходимости по вероятности).
Доказательство. Возьмем ![]() и
и ![]() В силу закона больших чисел (теорема Хинчина)
существует
В силу закона больших чисел (теорема Хинчина)
существует ![]() такое, что для любого
такое, что для любого ![]() справедливы неравенства
справедливы неравенства
![]()
Тогда с вероятностью не менее ![]() одновременно выполняются соотношения
одновременно выполняются соотношения
![]() (32)
(32)
При ![]() рассмотрим многочлен второй степени
рассмотрим многочлен второй степени
![]()
(см. формулу (29)). С вероятностью не
менее ![]() выполнены соотношения
выполнены соотношения
![]()
Если ![]() то знак
то знак ![]() в точках
в точках ![]() и
и ![]() определяется знаком линейного члена
определяется знаком линейного члена ![]() следовательно, знаки
следовательно, знаки ![]() и
и ![]() различны, а потому существует
различны, а потому существует ![]() такое, что
такое, что ![]() что и требовалось доказать.
что и требовалось доказать.
Теорема
2. Пусть выполнены условия теоремы 2 и, кроме того, для случайной величины х1, распределение которой соответствует значению параметра ![]() существует математическое ожидание
существует математическое ожидание

Тогда оценка минимального контраста имеет асимптотически нормальное распределение:
![]() (33)
(33)
для любого х, где Ф(x) – функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1.
Доказательство. Из центральной предельной теоремы вытекает, что числитель в правой части
формулы (30) асимптотически нормален с математическим ожиданием 0 и дисперсией ![]() Первое слагаемое в знаменателе формулы (30) в
силу условий (31) и закона больших чисел сходится по вероятности к
Первое слагаемое в знаменателе формулы (30) в
силу условий (31) и закона больших чисел сходится по вероятности к ![]() а второе слагаемое по тем же основанием и с
учетом теоремы 1 – к 0. Итак, знаменатель сходится по вероятности к
а второе слагаемое по тем же основанием и с
учетом теоремы 1 – к 0. Итак, знаменатель сходится по вероятности к ![]() Доказательство теоремы 2 завершает ссылка на
теорему о наследовании сходимости [3,параграф 2.4].
Доказательство теоремы 2 завершает ссылка на
теорему о наследовании сходимости [3,параграф 2.4].
Нотна оценки минимального контраста. Аналогично (30) нетрудно получить, что
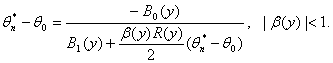 (34)
(34)
Следовательно, ![]() есть разность правых частей формул (30) и
(34). Найдем максимально возможное значение (т.е. нотну) величины
есть разность правых частей формул (30) и
(34). Найдем максимально возможное значение (т.е. нотну) величины ![]() при ограничениях (1) на абсолютные погрешности
результатов измерений.
при ограничениях (1) на абсолютные погрешности
результатов измерений.
Покажем,
что при ![]() для некоторого C>0 нотна имеет вид
для некоторого C>0 нотна имеет вид
![]()
![]() (35)
(35)
Поскольку ![]() то из (33) и (35) следует, что
то из (33) и (35) следует, что
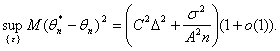 (36)
(36)
Можно сказать, что наличие
погрешностей ![]() приводит к появлению систематической ошибки
(смещения) у оценки метода максимального правдоподобия, и нотна является
максимально возможным значением этой систематической ошибки.
приводит к появлению систематической ошибки
(смещения) у оценки метода максимального правдоподобия, и нотна является
максимально возможным значением этой систематической ошибки.
В правой части (36) первое слагаемое – квадрат асимптотической нотны, второе соответствует статистической ошибке. Приравнивая их, получаем рациональный объем выборки
![]()
Остается
доказать соотношение (35) и вычислить С. Укажем сначала условия, при
которых![]() (по вероятности) при
(по вероятности) при ![]() одновременно с
одновременно с ![]()
Теорема
3. Пусть существуют константа ![]() и функции g1(x), g2(x), g3(x) такие, что при
и функции g1(x), g2(x), g3(x) такие, что при ![]() и
и ![]() выполнены неравенства (ср. формулу (27))
выполнены неравенства (ср. формулу (27))
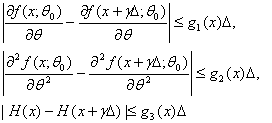
…(37)
при всех x. Пусть для случайной величины х1,
распределение которой соответствует ![]() ,
существуют m1 = Mg1(x1), m2 = Mg2(x1) и m3 = Mg3(x1). Пусть выполнены условия теоремы 1. Тогда
,
существуют m1 = Mg1(x1), m2 = Mg2(x1) и m3 = Mg3(x1). Пусть выполнены условия теоремы 1. Тогда ![]() (по вероятности) при
(по вероятности) при ![]() ,
, ![]() .
.
Доказательство проведем по схеме доказательства теоремы 1. Из неравенств (37) вытекает, что
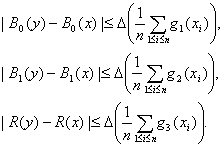 (38)
(38)
Возьмем ![]() и
и ![]() В силу закона больших чисел (теорема Хинчина)
существует
В силу закона больших чисел (теорема Хинчина)
существует ![]() такое, что для любого
такое, что для любого ![]() справедливы неравенства
справедливы неравенства
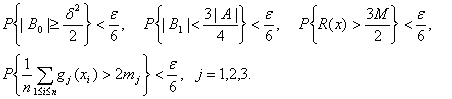
Тогда с вероятностью не менее ![]() одновременно выполняются соотношения
одновременно выполняются соотношения
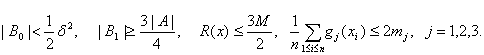
В силу (38) при этом
![]()
Пусть
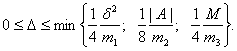
Тогда с вероятностью не менее ![]() одновременно выполняются соотношения (ср.
(32))
одновременно выполняются соотношения (ср.
(32))
![]()
Завершается доказательство дословным повторением такового в теореме 1, с единственным отличием – заменой в обозначениях x на y.
Теорема
4. Пусть выполнены условия теоремы 3 и, кроме того, существуют
математические ожидания (при ![]() )
)
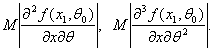 (39)
(39)
Тогда выполнено соотношение (35) с
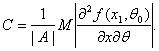 (40)
(40)
Доказательство. Воспользуемся следующим элементарным соотношением. Пусть a и b – бесконечно малые по сравнению с Z и B соответственно. Тогда с точностью до бесконечно малых более высокого порядка
![]()
Чтобы применить это соотношение к
анализу ![]() в соответствии с (30), (34) и теоремой 2,
положим
в соответствии с (30), (34) и теоремой 2,
положим
![]() В силу условий теоремы 4 при малых
В силу условий теоремы 4 при малых ![]() с точностью до членов более высокого порядка
с точностью до членов более высокого порядка
![]()
При ![]() эти величины бесконечно малы, а потому с
учетом сходимости B1(x) к А и теоремы 3
эти величины бесконечно малы, а потому с
учетом сходимости B1(x) к А и теоремы 3
![]()
с точностью до бесконечно малых более высокого порядка, где
![]()
Ясно, что задача оптимизации
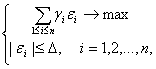 (41)
(41)
имеет решение

при этом максимальное значение
линейной формы есть ![]() Поэтому
Поэтому
![]() (42)
(42)
С целью упрощения правой части (42)
воспользуемся тем, что
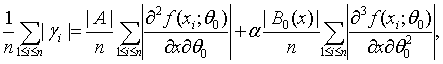 (43)
(43)
где ![]() Поскольку при
Поскольку при ![]()
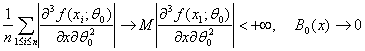
по вероятности, то второе слагаемое в (43) сходится к 0, а первое в силу закона больших чисел с учетом (39) сходится к СА2, где С определено в (40). Теорема 4 доказана.
Оценки
метода моментов. Пусть ![]() - некоторые функции. Рассмотрим аналоги
выборочных моментов
- некоторые функции. Рассмотрим аналоги
выборочных моментов
![]()
Оценки метода моментов имеют вид
![]()
(функции g и hj должны удовлетворять некоторым дополнительным условиям [39, с.80], которые здесь не приводим). Очевидно, что
![]()
![]() (44)
(44)
с точностью до бесконечно малых более высокого порядка, а потому с той же точностью
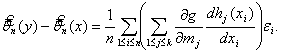 (45)
(45)
Теорема
5. Пусть при ![]() существуют математические ожидания
существуют математические ожидания
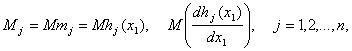
функция g дважды непрерывно дифференцируема в
некоторой окрестности точки ![]() Пусть существует функция
Пусть существует функция ![]() такая, что
такая, что
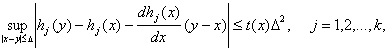 (46)
(46)
причем Mt(x1) существует. Тогда
![]()
с точностью до бесконечно малых более высокого порядка, причем
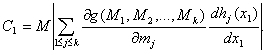
Доказательство теоремы 5 сводится к обоснованию проведенных ранее рассуждений, позволивших
получить формулу (45). В условиях теоремы 5 собраны предположения, достаточные
для такого обоснования. Так, условие (46) дает возможность обосновать
соотношения (44); существование 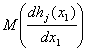 обеспечивает существование С1,
и т.д. Завершает доказательство ссылка на решение задачи оптимизации (41) и применение
закона больших чисел.
обеспечивает существование С1,
и т.д. Завершает доказательство ссылка на решение задачи оптимизации (41) и применение
закона больших чисел.
Полученные
в теоремах 4 и 5 нотны оценок минимального контраста и метода моментов,
асимптотические дисперсии этих оценок (см. теорему 2 и [40] соответственно)
позволяют находить рациональные объемы выборок, строить доверительные интервалы
с учетом погрешностей измерений, а также сравнивать оценки по среднему квадрату
ошибки (36). Подобное сравнение было проведено для оценок максимального
правдоподобия и метода моментов параметров гамма-распределения. Установлено,
что классический вывод о преимуществе оценок максимального правдоподобия [33,
с.99-100] неверен в случае ![]()
| Предыдущая |