

А.И.
Орлов
Эконометрика
Учебник. М.: Издательство "Экзамен", 2002.
| Предыдущая |
Глава 2. Выборочные исследования
2.3. Проверка однородности двух биномиальных выборок
Как сравнить две группы - мужчин и женщин, молодых и пожилых, и т.п.? В маркетинге это важно для сегментации рынка. Если две группы не отличаются по ответам, значит, их можно объединить в один сегмент и проводить по отношению к ним одну и туже маркетинговую политику, в частности, осуществлять одни и те же рекламные воздействия. Если же две группы различаются, то и относиться к ним надо по-разному. Это - представители двух разных сегментов рынка, требующих разного подхода при борьбе за их завоевание.
Эконометрическая постановка такова. Рассматривается вопрос с двумя возможными ответами, например, "да" и "нет". В первой группе из n1 опрошенных m1 человек сказали "да", а во второй группе из n2 опрошенных m2 сказали "да". В вероятностной модели предполагается, что m1 и m2 - биномиальные случайные величины B(n1 , p1 ) и B(n2 , p2 ) соответственно. (Запись B(n , p) означает, что случайная величина m, имеющая биномиальное распределение B(n , p) с параметрами n - объем выборки и p - вероятность определенного ответа (скажем, ответа "да"), может быть представлена в виде m = X1 + X2 +…+Xn , где случайные величины X1 , X2 ,…,Xn независимы, одинаково распределены, принимают два значения1 и 0, причем Р(Xi = 1) = р, Р(Xi = 0)= 1-р, i=1,2,…,n.)
Однородность двух групп означает, что соответствующие им вероятности равны, неоднородность - что эти вероятности отличаются. В терминах математической статистики: необходимо проверить гипотезу однородности
H0 : p1 = p2
при альтернативной гипотезе
H1 : p1 ![]() p2 .
p2 .
(Иногда
представляют интерес односторонние альтернативные гипотезы ![]() и
и ![]() .)
.)
Оценкой вероятности р1 является частота р1*=m1/n1, а оценкой вероятности р2 является частота р2*=m2/n2 . Даже при совпадении вероятностей р1 и р2 частоты, как правило, различаются, как говорят, "по чисто случайным причинам". Рассмотрим случайную величину р1* - р2*. Тогда
M(р1* - р2*) = р1 - р2 , D(р1* - р2*) = р1 (1 - р1 )/ n1 + р2 (1-р2 )/ n2 .
Из теоремы Муавра-Лапласа и теоремы о наследовании сходимости [4, п.2.4] следует, что
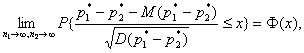
где ![]() - функция стандартного нормального распределения с
математическим ожиданием 0 и дисперсией 1. Для практического применения этого
соотношения следует заменить неизвестную эконометрику дисперсию разности частот
на оценку этой дисперсии:
- функция стандартного нормального распределения с
математическим ожиданием 0 и дисперсией 1. Для практического применения этого
соотношения следует заменить неизвестную эконометрику дисперсию разности частот
на оценку этой дисперсии:
D*(р1* - р2*) = р*1 (1 - р*1 )/ n1 + р*2 (1-р*2 )/ n2 .
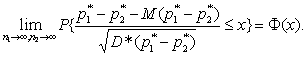 |
С помощью указанной выше математической техники можно показать, что
При справедливости гипотезы однородности M(р1* - р2*) = 0. Поэтому правило принятия решения при проверке однородности двух выборок выглядит так:
1. Вычислить статистику
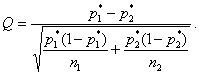
2. Сравнить значение модуля статистика |Q| с граничным значением K. Если |Q|<K, то принять гипотезу однородности H0 . Если же |Q|>K, то заявить об отсутствии однородности и принять альтернативную гипотезу H1 .
Граничное значение К определяется выбором уровня значимости статистического критерия
проверки однородности. Из приведенных выше предельных
соотношений следует, что при справедливости гипотезы однородности H0 для уровня значимости ![]() имеем (при
имеем (при ![]()
![]()
Следовательно, граничное значение в зависимости от уровня значимости целесообразно выбирать из условия
![]()
Здесь ![]() - функция, обратная к функции стандартного нормального распределения.
В социально-экономических исследованиях наиболее распространен 5% уровень
значимости, т.е.
- функция, обратная к функции стандартного нормального распределения.
В социально-экономических исследованиях наиболее распространен 5% уровень
значимости, т.е. ![]() Для него К = 1,96.
Для него К = 1,96.
Пример. Пусть в первой группе из 500 опрошенных ответили "да" 200, а во второй группе из 700 опрошенных сказали "да" 350. Есть ли разница между генеральными совокупностями, представленными этими двумя группами, по доле отвечающих "да"?
Уберем из формулировки примера термин "генеральная совокупность".
Пусть из 500 опрошенных мужчин ответили "да, я люблю пепси-колу" 200, а из 700 опрошенных женщин 350 сказали "да, я люблю пепси-колу". Есть ли разница между мужчинами и женщинами по доле отвечающих "да" на вопрос о любви к пепси-коле?
В рассматриваемом примере нужные для расчетов величины
таковы: ![]() Вычислим статистику
Вычислим статистику
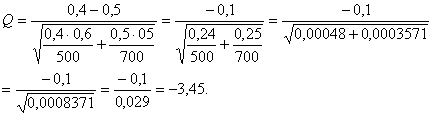
Поскольку |Q| = 3,45 > 1,96, то необходимо отклонить нулевую гипотезу т принять альтернативную. Таким образом, мужчины и женщины отличаются по рассматриваемому признаку - любви к пепси-коле.
Необходимо отметить, что результат проверки гипотезы однородности зависит не только от частот, но и от объемов выборок. Предположим, что частоты (доли) зафиксированы, а объемы выборок растут. Тогда числитель статистики Q не меняется, а знаменатель уменьшается, значит, вся дробь возрастает. Поскольку знаменатель стремится к 0, то дробь возрастает до бесконечности и рано или поздно превзойдет любую границу. Есть только одно исключение - когда в числителе стоит 0. Следовательно, вывод эконометрика должен выглядеть так: "различие обнаружено" или "различие не обнаружено". Во втором случае различие, возможно, было бы обнаружено при увеличении объемов выборок.
Как и для доверительного оценивания вероятности, во ВЦИОМ разработаны две полезные таблицы, позволяющие оценить вызванные чисто случайными причинами допустимые расхождения между частотами в группах. Эти таблицы рассчитаны при выполнении нулевой гипотезы однородности и соответствуют ситуациям, когда частоты близки к 50% (табл.7) или к 20% (табл.8). Если наблюдаемые частоты - от 30% до 70%, то рекомендуется пользоваться первой из этих таблиц, если от 10% до 30% или от 70% до 90% - то второй. Если наблюдаемые частоты меньше 10% или больше 90%, то теорема Муавра-Лапласа и основанные на ней асимптотические формулы дают не очень хорошие приближения, целесообразно применять иные, более продвинутые математические средства, в частности, приближения с помощью распределения Пуассона.
Табл.7. Допустимые расхождения (в %) между частотами в двух группах
в случае, когда наблюдаются частоты от 30% до 70%
Объемы Групп |
750 |
600 |
400 |
200 |
100 |
750 |
6 |
7 |
7 |
10 |
12 |
600 |
7 |
8 |
8 |
11 |
13 |
400 |
7 |
8 |
10 |
11 |
14 |
200 |
10 |
11 |
11 |
13 |
16 |
100 |
12 |
13 |
14 |
16 |
18 |
Табл.8. Допустимые расхождения (в %) между частотами в двух группах в случае, когда наблюдаются частоты от 10% до30% или от 70% до 90%
Объемы Групп |
750 |
600 |
400 |
200 |
100 |
750 |
5 |
5 |
6 |
8 |
10 |
600 |
5 |
6 |
7 |
8 |
10 |
400 |
6 |
7 |
8 |
9 |
11 |
200 |
8 |
8 |
9 |
10 |
12 |
100 |
10 |
10 |
11 |
12 |
14 |
В условиях разобранного выше примера табл.7 дает допустимое расхождение 7%. Действительно, объем первой группы 500 отсутствует в таблице, но строки, соответствующие объемам 400и 600, совпадают для первых двух столбцов слева. Эти столбцы соответствуют объемам второй группы 750 и 600, между которыми расположен объем 700, данный в примере. Он ближе к 750, поэтому берем величину расхождения, стоящую на пересечении первого столбца и второй (и третьей) строк, т.е. 7%. Поскольку реальное расхождение (10%) больше, чем 7%, то делаем вывод о наличии значимого различия между группами. Естественно, этот вывод совпадает с полученным ранее расчетным путем.
Допустимое расхождение ![]() между частотами нетрудно получить расчетным путем. Для этого
достаточно воспользоваться формулой для статистики Q и определить, при каком максимальном расхождении
частот все еще делается вывод о том, что верна гипотеза однородности. Следовательно, допустимое расхождение
между частотами нетрудно получить расчетным путем. Для этого
достаточно воспользоваться формулой для статистики Q и определить, при каком максимальном расхождении
частот все еще делается вывод о том, что верна гипотеза однородности. Следовательно, допустимое расхождение ![]() находится из уравнения
находится из уравнения
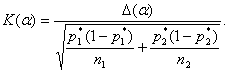
Таким образом,
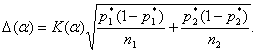
Для
данных примера ![]() = 1,96
= 1,96 ![]() 0,029 = 0,057, или 5,7%, для уровня значимости 0,05. .
0,029 = 0,057, или 5,7%, для уровня значимости 0,05. .
Для других уровней значимости надо использовать другие
коэффициенты ![]() Так, K(0,01) = 2,58 для уровня значимости 1% и
K(0,10) = 1,64 для уровня значимости 10%. Для данных примера
Так, K(0,01) = 2,58 для уровня значимости 1% и
K(0,10) = 1,64 для уровня значимости 10%. Для данных примера ![]() = 2,58
= 2,58 ![]() 0,029 = = 0,7482
0,029 = = 0,7482 ![]() 0,075, или 7,5%, для
уровня значимости 0,01. Если округлить до ближайшего целого числа процентов, то
получим 7%, как при использовании таблицы 7 выше.
0,075, или 7,5%, для
уровня значимости 0,01. Если округлить до ближайшего целого числа процентов, то
получим 7%, как при использовании таблицы 7 выше.
Анализ таблиц 7 и 8 показывает, что для констатации различия частоты должны отличаться не менее чем на 6%, а при некоторых объемах выборок - более чем на 10%, при объемах выборок 100 и 100 - на 19%. Если частоты отличаются на 5% или менее, можно сразу сказать, что эконометрический анализ приведет к выводу о том, что различие не обнаружено (для выборок объемов не более 750).
В связи с этим возникает вопрос: каково типовое отличие частот в двух выборках из одной и той же совокупности? Разность частот в этом случае имеет нулевое математическое ожидание и дисперсию
![]()
Величина р(1-р) достигает максимума при р=1/2, и этот максимум равен 1/4. Если р=1/2, а объемы двух выборок совпадают и равны 500, то дисперсия разности частот равна
![]()
Следовательно,
среднее квадратического отклонение ![]() равно 0,032, или 3,2%. Поскольку для стандартной нормальной
случайной величины в 50% случаев ее значение не превосходит по модулю 0,67 (а в
50% случаев - больше 0,67), то типовой разброс равен 0,67
равно 0,032, или 3,2%. Поскольку для стандартной нормальной
случайной величины в 50% случаев ее значение не превосходит по модулю 0,67 (а в
50% случаев - больше 0,67), то типовой разброс равен 0,67![]() , а в рассматриваемом случае- 2,1%. Приведенные соображения
дают метод контроля за правильностью проведения
повторных опросов. Если частоты излишне устойчивы, это подозрительно!
, а в рассматриваемом случае- 2,1%. Приведенные соображения
дают метод контроля за правильностью проведения
повторных опросов. Если частоты излишне устойчивы, это подозрительно!
| Предыдущая |